



Most teams building LLM evaluation pipelines spend a lot of time on the judge itself, which model to use, how to write the rubric, and which dimensions to score. Almost none of that effort goes into evaluating whether the judge is actually right.
The implicit assumption is that a capable model with a clear prompt will produce reliable verdicts. That assumption breaks in a specific, predictable way: the judge learns to ask "does this sound correct?" when the right question for any LLM-as-a-judge evaluation is "is each claim in this response directly traceable to the retrieved context?" These look like the same question. They produce completely different behavior in the failure cases that matter most.
Assumed knowledge: you've built or used an LLM judge and understand the basic setup.
What faithful actually means in a RAG context
For a RAG-based agent, faithfulness is the most common evaluation dimension and the hardest to get right. A faithful response is one in which every factual claim, every number, rule, product feature, negation, or comparison is directly and explicitly supported by the retrieved context and not implied. Not consistent with what the model knows from training. Explicitly present in the passage that was retrieved.
This is a stricter standard than it sounds. An agent can produce a response that is factually accurate in the world but unfaithful to the retrieved context, because it drew on knowledge outside that context. A judge evaluating faithfulness has to catch that. In practice, a generic faithfulness prompt doesn't.
Where the generic judge fails
The failure mode that appears most consistently in production judges is cross-document attribution error: the agent retrieves context from document A, but the response contains a claim that belongs to document B. The claim is accurate in the abstract. It is not supported by what was retrieved. The judge, operating on surface plausibility rather than claim-level traceability, scores the response as faithful.
In a test set of 30 labeled examples (21 faithful responses and nine unfaithful ones), a generic GPT-4.1 judge with a standard faithfulness prompt produced these results:
The judge performed well on the easy case, identifying correct responses as correct. It failed on the cases that matter for safety and reliability. A 100% false negative rate on hallucinations means the evaluation pipeline is providing false confidence at exactly the point where confidence is most dangerous.
Three failure patterns accounted for all nine misses.
- Cross-product attribution is the most common. The agent retrieves context about product A, the response states a rule that belongs to product B, a similar but distinct product. The retrieved context for product A contains no such rule. The judge sees plausible-sounding content and passes it. It never checks which product the rule actually belongs to.
- Training data injection is subtler. The agent correctly answers part of a question using retrieved context, then adds a claim about a related entity that is not in the retrieved passage, drawn instead from training data. The claim may be accurate. The judge scores the full response as faithful because it doesn't distinguish between information from the retrieved context and information from parametric memory.
- Number misattribution is the hardest for a generic judge to catch. The retrieved context contains a figure that belongs to entity A. The response cites that figure in answer to a question about entity B. The judge finds the number in the context window, matches it to the number in the response, and concludes the response is supported. Entity attribution doesn't enter the reasoning at all.
The root cause: it's a reasoning problem
The generic judge fails not because it lacks knowledge of what faithfulness means, but because it doesn't apply that knowledge at the right level of granularity.
A generic faithfulness prompt asks the judge to evaluate whether the response is faithful to the context. The judge interprets this as: does the response sound consistent with the retrieved information? It checks for gross inconsistencies and obvious fabrications. What it doesn't do is extract each discrete factual claim and verify that claim independently against the retrieved passages.
The judge knows the definition of faithfulness. It doesn't perform the reasoning steps required to apply that definition correctly: enumerate claims, check each one against the specific supporting passage, verify entity attribution, and flag truncated context as insufficient support.
Human annotations are what make calibration possible. When a domain expert looks at the same input the judge failed on and records the correct verdict, they're producing something more valuable than a label: they're producing evidence of where the judge's reasoning diverged from correct reasoning. Calibration uses that evidence to rewrite the prompt, not to inject new knowledge into the model, but to restructure the reasoning steps the model applies. The model already knows what faithfulness means. It needs to be told how to check for it, claim by claim.
Measuring LLM judge accuracy: the 7-metric ensemble
A single accuracy score won't always surface the failure. In the test set above, the generic judge had 20/21 accuracy on faithful responses. Reported as an aggregate accuracy metric, that looks reasonable, but hides a 0/9 recall on the failure class.
Evaluating judge quality requires an ensemble of metrics that simultaneously expose different blind spots. The seven metrics used in Galtea's calibration framework:
The final alignment score is the average across all seven. Individual metrics deceive in specific ways. High accuracy with low Cohen's Kappa means the judge is getting verdicts right by chance, not by understanding; it would produce similar accuracy on a shuffled dataset. High precision with low recall means the judge is conservative: when it calls something a failure, it's usually right, but it misses most of the real failures. Neither configuration is trustworthy in production.
Report alignment score separately for each evaluation dimension, faithfulness, relevance, and factual accuracy, rather than as a single average. An aggregate alignment of 0.80 can hide a faithfulness alignment of 0.55, which is close to chance on a binary classification task.
How to calibrate your LLM judge
Calibration is the process of improving the judge's behaviour until the ensemble alignment score reaches a threshold you've defined as acceptable. Three inputs are required before you start.
The golden dataset. Pull examples from your actual evaluation distribution, real queries, real retrieved context, and real agent responses. Have domain experts label each one with the correct verdict (not generalist annotators; domain knowledge matters here). For binary classification tasks, 30 labeled examples are a viable starting point if the failure classes are well-represented; 200+ is safer for production deployment gates. Measure inter-rater agreement before using the set. If two human raters agree on fewer than 80% of examples, the task definition is ambiguous; calibrate the rubric, not the judge.
The baseline. Run the current judge prompt against the golden dataset, compute all seven metrics, and record the result. This is Step 0. Every subsequent iteration is measured against it.
Prompt optimization. The most effective approach is iterative prompt rewriting using a meta-LLM as the optimizer, inspired by OPRO (Optimization by PROmpting). The loop: feed the optimizer the current prompt and the worst-performing examples from the golden dataset (complete inputs, retrieved contexts, and agent responses included); generate candidate prompts each applying a different rewrite strategy (general improvement, fix false positives, fix false negatives, add an explicit rubric, or radical simplification); evaluate every candidate against the full golden dataset using the seven-metric ensemble; keep the highest-scoring candidate; log all tested prompts and scores to prevent cycling back to already-failed configurations; repeat until alignment plateaus or hits a ceiling (≥0.95 in this implementation).
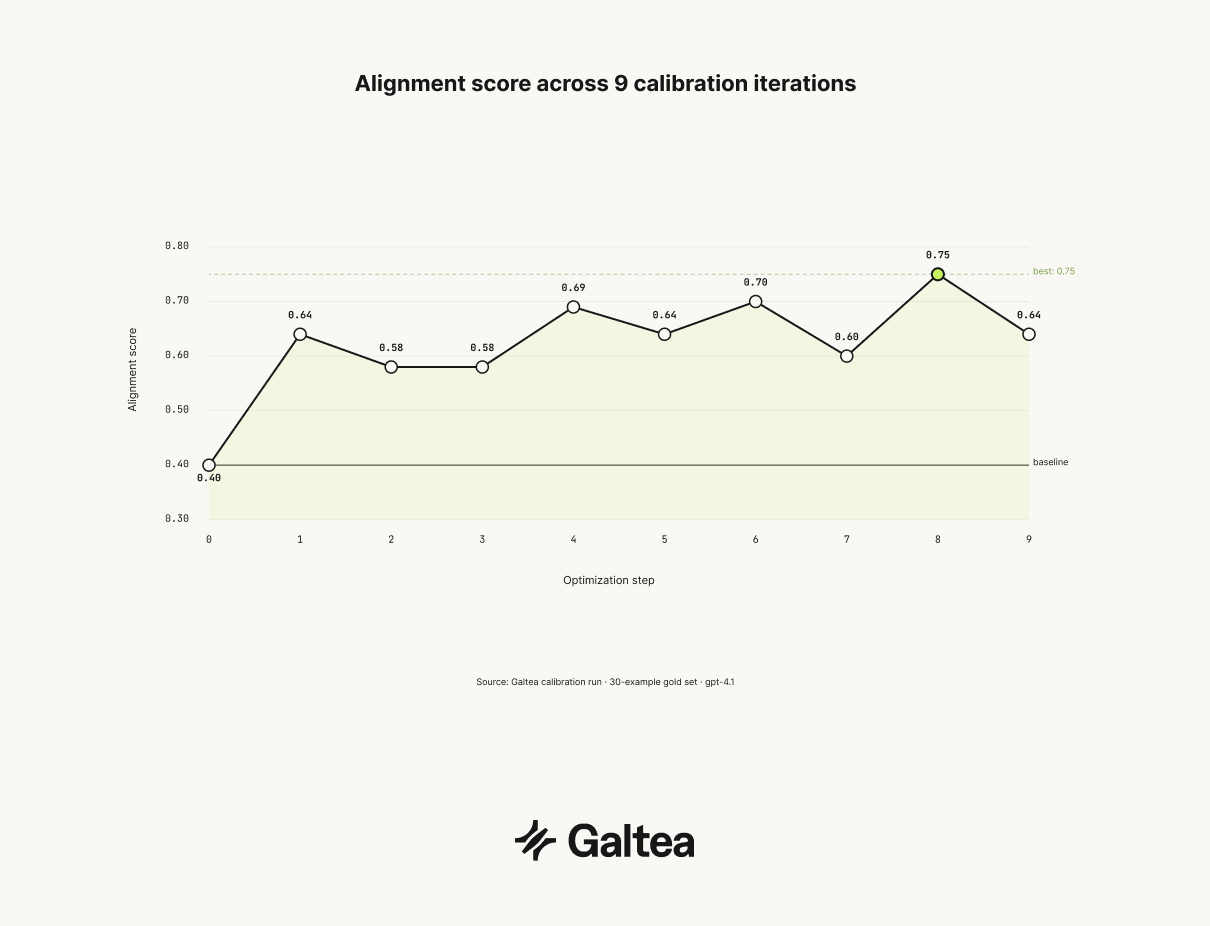
In one calibration run on a 30-example golden dataset, the optimization loop ran nine iterations before stabilising:
Alignment doesn't improve monotonically. Some iterations regress. The score log prevents the optimizer from cycling back to configurations that already failed, which is what stops it from getting stuck.
What the calibrated judge learned

"Evaluate whether the assistant's response is faithful to the retrieved source documentation. A response is faithful if every factual claim is directly supported by the context. A response is unfaithful if it adds, modifies, or presents assumptions as facts. Score 1 if faithful, 0 if any unsupported claims."
The generic prompt was 10 lines. The calibrated prompt is 59 lines. The difference is not length; it's the reasoning structure. The generic prompt sounds reasonable, but catches zero out of nine hallucinations.
The optimizer derived six specific reasoning directives from the pattern of human disagreements. Before evaluating anything, the judge must first extract every discrete factual claim from the response, numbers, rules, features, negations, and comparisons as a separate enumeration step. Then each claim gets verified independently against the retrieved context: exact match on numbers, units, scope, and entity name, not surface consistency.
Two instructions address the failure modes that generic prompts miss entirely. Absence of evidence is not evidence: the judge must never treat "not mentioned" as support for a negative claim, and any retrieved sentence that is cut off or truncated counts as zero support for whatever follows the cut. Entity attribution gets its own verification step; claims must match the correct product, person, or document exactly, with no transfer of details between similarly named entities.
The scoring rule is strict: one ungrounded claim equals Score 0, regardless of how many other claims are correct.
After calibration: six out of nine hallucinations detected, alignment score 0.75, two false positives out of 21 faithful responses. From 0% recall on the failure class to 67%, using nine human annotations as the only training signal.
Cost vs. alignment: the model selection result
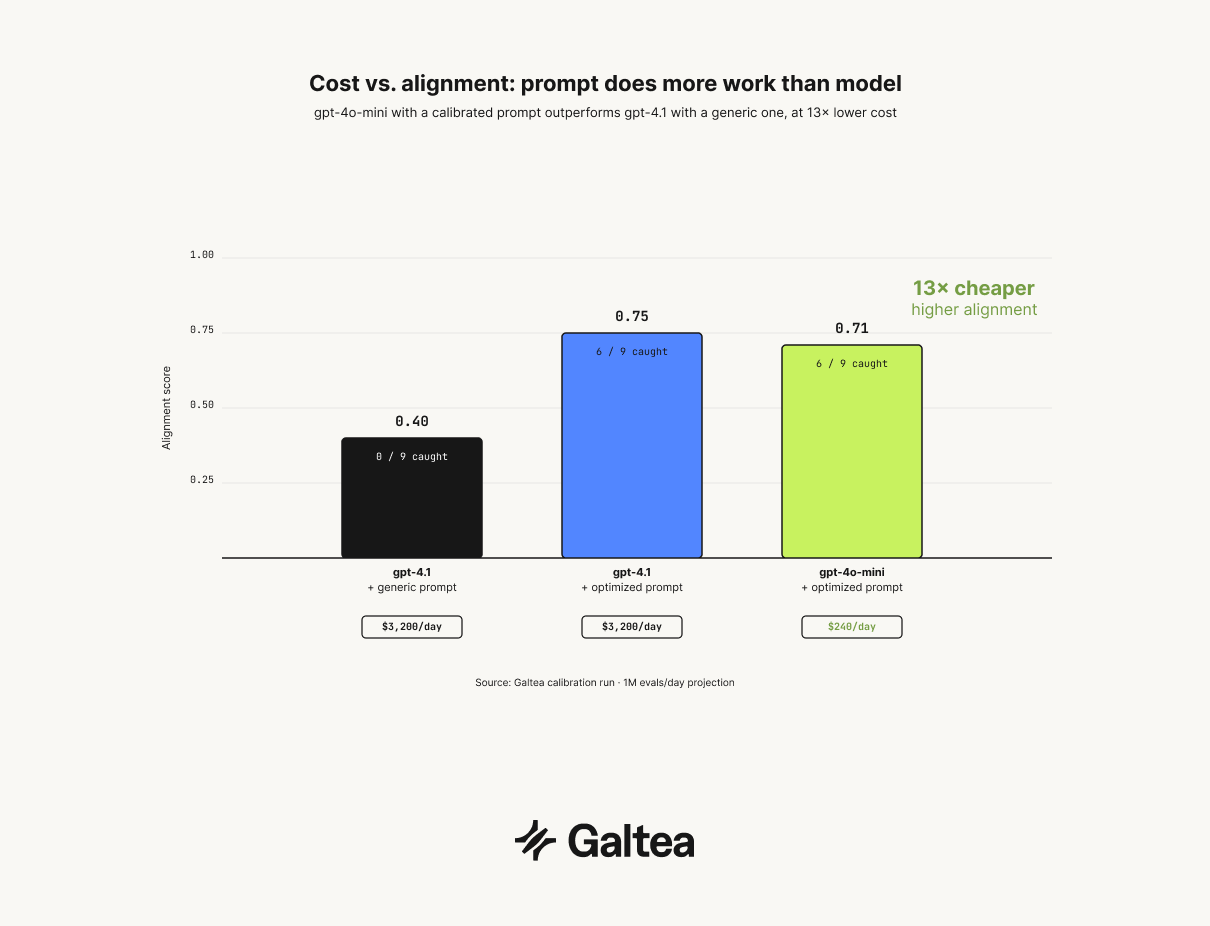
Prompt calibration changes the model selection decision in a way most teams don't anticipate. After calibrating on a capable model, the same optimized prompt was transferred to a smaller, cheaper model. Results:
This is a controlled comparison: all three configurations used the same 30-example gold set, the same evaluation metrics, and the same retrieved contexts. The only variable was the judge model and prompt.
gpt-4o-mini with the optimized prompt achieves 0.71 alignment while running at roughly 13x lower cost per inference than gpt-4.1. At one million evaluations per day (a reasonable volume for a production agent serving active users), that gap translates to approximately $3,200/day on gpt-4.1 versus $240/day on gpt-4o-mini, a difference of roughly $1.1M annually, at a higher alignment score. The cheaper model wins on both dimensions.
The prompt is doing more work than the model. gpt-4.1 with a generic prompt is not a substitute for a calibrated prompt on GPT-4o-mini; it's the wrong tradeoff. If your judge runs on every production response, deploy the calibrated, cheaper model. At 0.71 alignment, it outperforms the default configuration on every metric that matters, and the cost difference compounds at scale.
The continuous cycle and when to stop
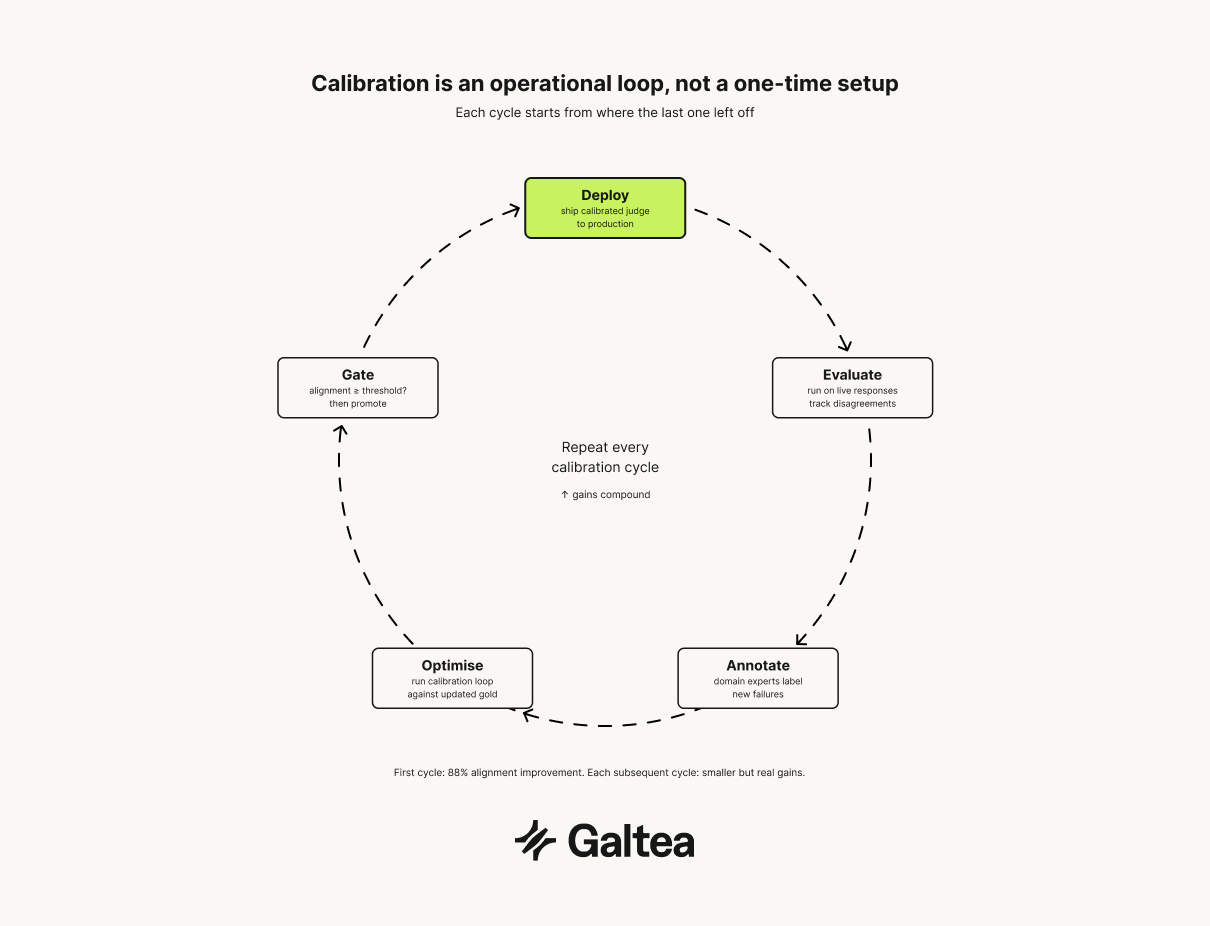
A calibrated judge degrades. As the system under evaluation improves, the output distribution shifts, and the judge will encounter examples outside the range it was calibrated on. Treat calibration as an operational loop: evaluate, annotate disagreements, optimize, deploy, re-annotate remaining failures, repeat.
The first cycle produces the biggest gains. One round of calibration on nine annotated disagreements moved alignment from 0.40 to 0.75, an 88% improvement. Each subsequent cycle produces smaller but real gains. More annotations improve the optimizer's signal; a better signal produces judges that catch more failures at lower cost.
There are three legitimate stopping conditions. Alignment above 0.80 with iterations producing gains below 0.02 per step: incremental prompt changes at that point are calibrating to variance in the golden dataset, not to genuine failure modes. Human inter-rater agreement below 0.6 Cohen's Kappa on the golden dataset: if raters disagree with each other at that rate, the evaluation task is ambiguous, and further calibration will optimize for noise. The third is a product decision: a judge catching six of nine hallucinations may be insufficient for a high-stakes domain and acceptable for a developer productivity tool. Define that threshold before you start calibrating, not after.
Do not stop because the judge performs well on the passing cases. The generic judge correctly identified 20 out of 21 faithful responses. That number in isolation would suggest it was working. It wasn't.



