



TL;DR — The mental models and tools that work for traditional software testing break on language models. Outputs are probabilistic, quality is multidimensional, models change under you without a deploy, and the thing you're testing can fail silently in ways no assertion will catch. LLM evaluation is a different discipline, not an extension of the one you already have.
Why software testing instincts fail for LLM evaluation
When engineering teams first need to evaluate an LLM, they reach for what they know. Write some test cases. Assert the output matches an expected value. Run on every PR. This feels right — it's how quality works everywhere else in the stack.
It doesn't work here. Not because the instinct is wrong, but because language models have properties that break every assumption those tools were built on.
The gap isn't tooling. It's the mental model.
Assumption 1: same input, same output

Every traditional testing approach depends on determinism. Given the same input and the same code, the output is the same. That's what makes assertions work.
Language models are not deterministic. Temperature > 0 means the same prompt produces different outputs on every call. Even at temperature 0, minor implementation changes between model versions can shift outputs. The code doesn't change. The output does.
This means exact-match assertions — the most common form of unit test — are structurally wrong for evaluating LLM output quality. They'll fail on valid responses and pass on invalid ones, depending on which specific tokens the model happened to produce.
The replacement is not a better assertion. It's a different evaluation method: rubric-based scoring, reference comparison, or LLM-as-a-judge — each designed to operate on a range of valid outputs rather than a single expected string.
Assumption 2: pass/fail covers quality
A unit test returns green or red. That binary is useful precisely because the behaviour being tested is binary — the function either returns the right value or it doesn't.
LLM output quality is not binary. A response can be mostly correct with a factual error in the third sentence. It can answer the question while citing something that wasn't in the retrieved context. It can be technically accurate but so verbose that users stop reading halfway through. None of these are caught by a pass/fail check. None of them show up as test failures. All of them degrade the product.
Measuring LLM quality requires graded scoring across multiple dimensions — correctness, faithfulness, relevance, safety — each with its own metric and its own acceptable failure rate. A single green/red result flattens the information you need to diagnose what's actually wrong.
Assumption 3: you control what changes
In traditional software, the system changes when you deploy. Your test suite is a record of intended behaviour, and it fails when a deploy breaks something. The relationship is clean: change in code → potential failure in tests.
Language models break this relationship in two ways.
First, model providers update underlying weights without changing the API identifier. OpenAI updated GPT-4 Turbo's weights multiple times without bumping the model version string — documented in developer forums after the fact. Your prompts didn't change. Your code didn't change. The model's behaviour did. No CI suite catches this.
Second, the input distribution shifts as new users find the product. The model that performed well on your internal test set may perform poorly on the long tail of queries real users send — not because anything changed in the system, but because the system was never tested on those inputs. Traditional software doesn't have this problem: `add(2, 3)` doesn't start returning wrong values because new users started calling it.
This is why LLM evaluation has a production monitoring layer that has no parallel in software testing: continuously scoring sampled live traffic, watching for drift that doesn't correlate with any deploy you made.
Assumption 4: test coverage is achievable
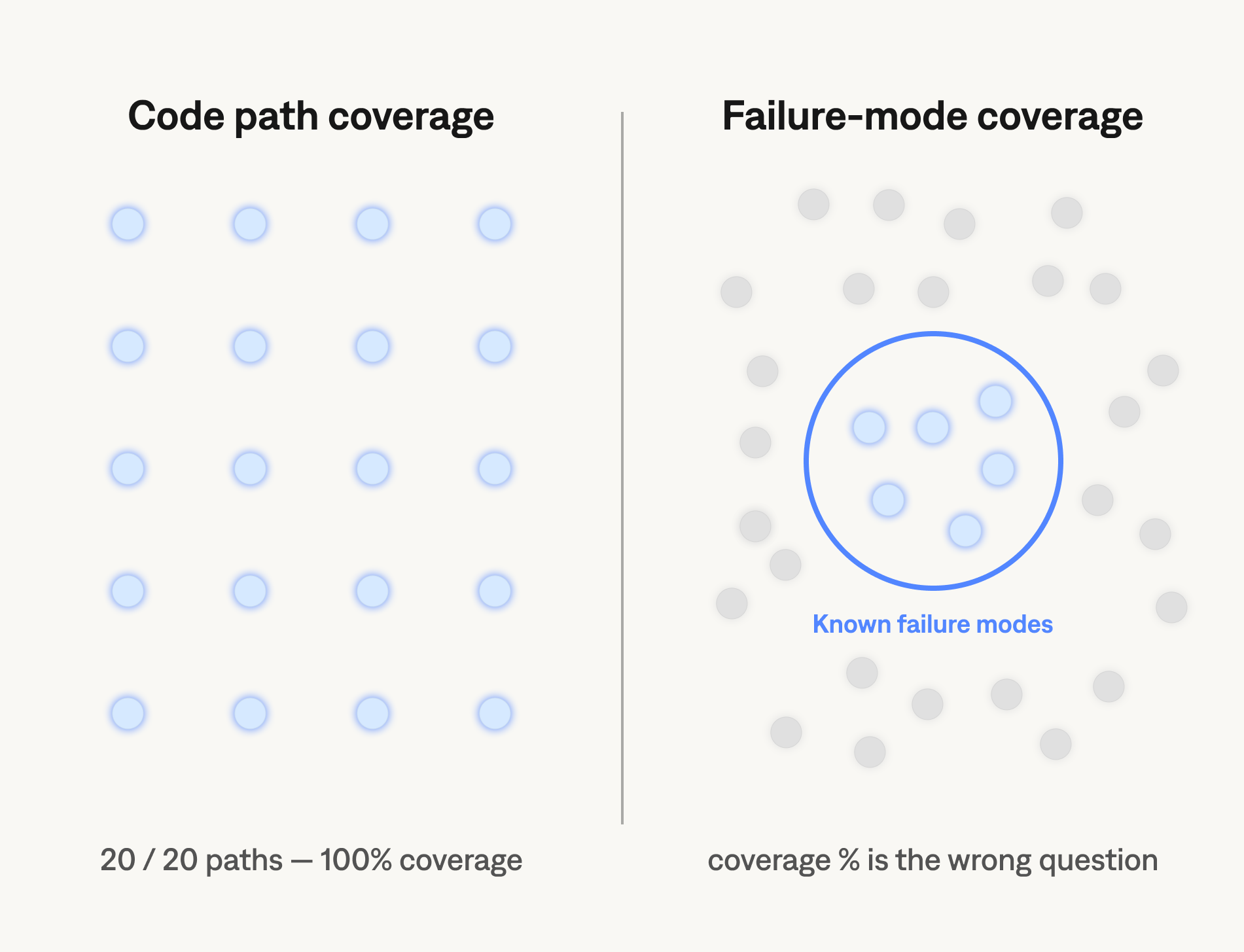
A software test suite can, in principle, cover every code path. Coverage tools measure exactly how close you are. 100% branch coverage is a real, achievable target.
For language models, the input space is effectively infinite. You cannot enumerate the queries users will send. You cannot write a test for every failure mode before it occurs. The standard for "enough coverage" isn't a percentage — it's whether your evaluation set contains enough examples of the failure modes that matter for your application.
This changes the dataset-building question fundamentally. You're not trying to cover the space. You're trying to cover the failure modes — specifically the ones that have already occurred or are most likely to occur. The right dataset comes from bottom-up analysis of real failures, not top-down enumeration of possible inputs.
Assumption 5: the dev team defines quality

In software, the engineering team defines what correct behaviour looks like. The spec is in the code. When a test fails, the engineer can tell you what the expected value was and why.
For LLM evaluation, quality criteria require domain expertise to define. What makes a customer support response correct is a customer support question — one that requires knowledge of the product, the policy, and the user expectation. What makes a legal document summary faithful is a legal question. The engineering team can build the evaluation infrastructure. They usually can't write the rubric.
This is why the most effective golden datasets are built with one domain expert doing the initial grading — not a committee, not outsourced annotation, but the person who owns the product and understands what good looks like. That grading session is where quality criteria get defined in practice, not in a spec document.
What this means in practice
The goal isn't to stop doing software testing. Unit tests that check output schema, label membership, and response length are still useful — they're fast, cheap, and catch obvious breakage. The goal is to stop mistaking those tests for quality evaluation.
LLM evaluation sits above software testing, not instead of it. It handles the layer that assertions can't reach: does the output actually do what the application needs it to do, across the distribution of real inputs, over time.
For the full evaluation framework — traces, golden datasets, judge calibration, CI regression, and production monitoring, see LLM Evaluation: A Practitioner's Guide.



