



TL;DR — LLM evaluation measures whether a language model does what your specific application needs it to do — correctness, faithfulness, relevance, and safety are four different dimensions that each require a separate metric. Three methods do the measuring: reference-based metrics for constrained outputs, LLM-as-a-judge for open-ended quality, and human evaluation to establish ground truth. Before any of that works, you need traces: structured logs of every input, retrieved chunk, tool call, and output your system produces. Start with 50 real failures, have one domain expert grade them binary pass/fail with written critiques, calibrate a judge prompt against those verdicts, and gate every deployment on the metric that corresponds to your most expensive failure mode.
You ship a new model version on Thursday. The demo passes on Friday morning. Two weeks later, 180 support tickets about wrong answers, a VP of Customer Success who wants a post-mortem, and no record of what the previous model was doing on the inputs that are now failing.
Shipping more carefully won't help. The problem isn't the deploy cadence; it's that nobody measured whether quality had moved before this model saw real traffic. The demo isn't a measurement. Neither are MMLU scores, which is what most model selection processes start with (and which tell you almost nothing about application-level performance). A model ranking second on MMLU is not necessarily better at summarizing enterprise legal documents than the model ranking sixth. The benchmark tests broad general reasoning. Your task is not general.
LLM evaluation is how you measure the specific thing: does this model do what my application needs it to do, on the inputs my users actually send, failing in the ways that cost the business money? Not "is this a good model in the abstract," and not "does this beat the previous version on HellaSwag."
What LLM evaluation actually measures
LLM evaluation is not running benchmarks. It's answering one question: does this model do what my application needs it to do? That question has three distinct layers, and most teams only measure one of them.
- Functional quality is whether the model produces correct outputs for its task. For a customer support bot, that means accurate answers. For a code generator, that means code that compiles and passes tests. For a summarizer, that means summaries that preserve the key facts without adding false ones.
- Safety and behavior is whether the model stays within the boundaries you've defined. Does it refuse to produce harmful content? Does it stay on-topic? Does it handle edge cases and adversarial inputs without breaking?
- Production stability is whether functional quality and safety hold over time, across model updates, prompt changes, and shifts in real user inputs. This is the layer that most teams discover during an incident rather than before one.
The four dimensions to measure
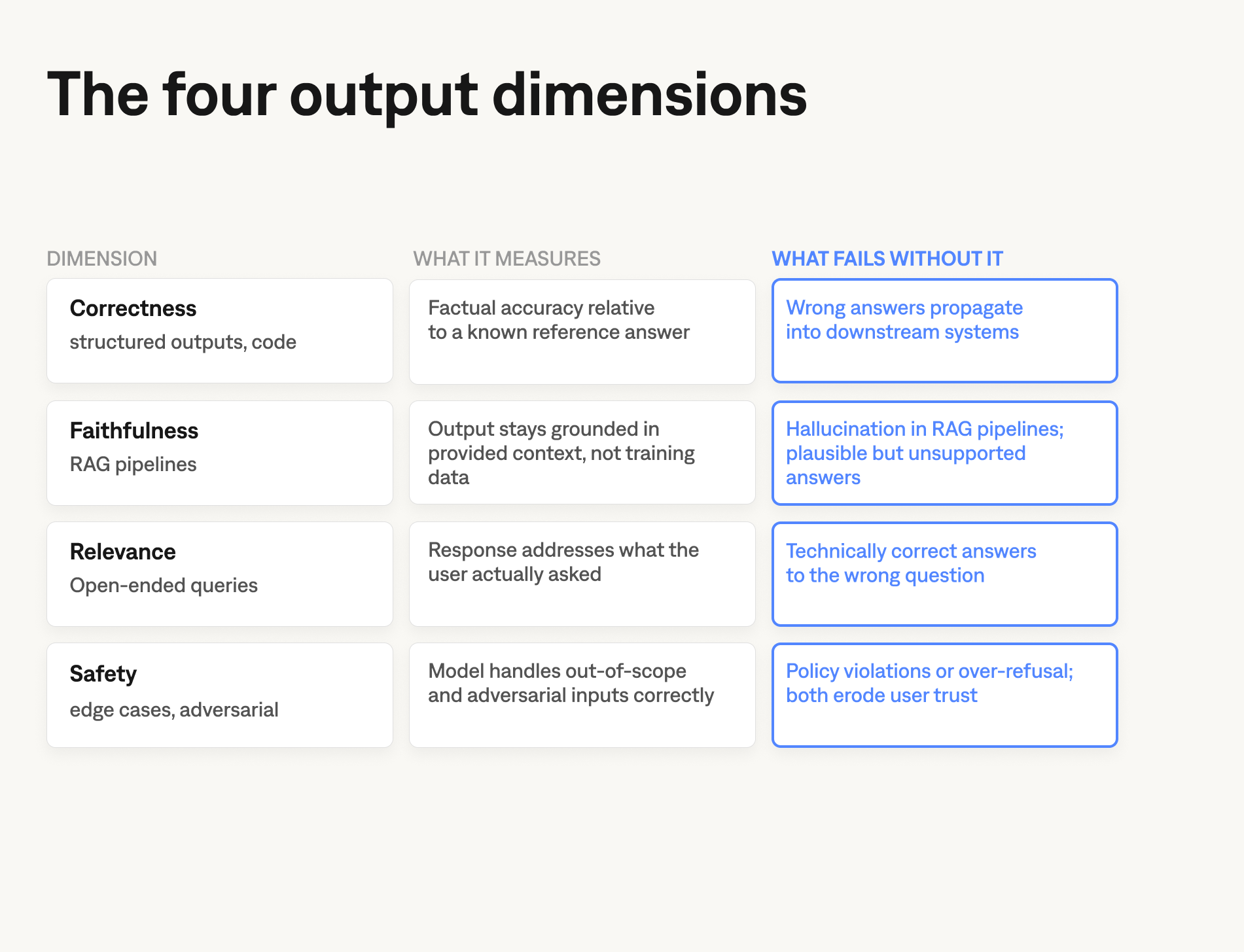
Output quality is not one thing. Teams that track "quality" with a single number miss the specific failures that cause production incidents. Four dimensions each require a separate metric or evaluation method.
- Correctness is whether the model's output is factually accurate relative to a known answer. Measurable with exact match for structured outputs, ROUGE for extractive tasks, or an LLM judge comparing to a reference answer. Correctness matters most for tasks where wrong answers have concrete consequences: medical queries, financial data, code generation.
- Faithfulness is whether the model's output stays grounded in provided context. A model can produce fluent, plausible-sounding output that contradicts the retrieved documents. A model that scores well on correctness against its training data but hallucinates details from provided documents is a faithfulness problem, not a correctness problem. They require different fixes.
- Relevance is whether the response addresses what the user actually asked. Distinct from correctness (you can give a correct answer to the wrong question) and from faithfulness (a response can be grounded in context but still tangential). Relevance is the dimension that surfaces when users report "it keeps answering questions I didn't ask."
- Safety and refusal behavior is whether the model handles out-of-scope, adversarial, and sensitive inputs appropriately. Both false positives and false negatives are production incidents. A model that over-refuses erodes user trust as surely as one that violates safety policies.
Five evaluation stages, and why conflating them is the main mistake

Evaluation is not a single thing that happens after a change. Five stages each require different methods, different datasets, and different failure thresholds. Teams that treat them as one stage end up with evals that don't catch what actually breaks.
- Development: every commit. Unit-test-style checks that run in milliseconds: does the output contain a phone number when it shouldn't? Does the classifier return one of the four expected labels? Does the JSON parse without errors? These are not quality evaluations — they're sanity checks. They catch obvious breakage before anything touches a judge. Teams that skip this and start at CI evals pay for it in slow, expensive pipelines doing work that a 5ms check could have filtered out.
- Pre-release: before any new model version or major prompt change. Run against a red-team dataset covering edge cases, adversarial inputs, and the failure modes listed in the OWASP Top 10 for LLM Applications (prompt injection, insecure output handling, and excessive agency among them). The golden dataset covers failures you have already seen. Pre-release adversarial testing finds the ones you haven't.
- CI regression: every pull request. Every PR that touches a prompt, a model version, or a retrieval configuration triggers an eval run against the golden dataset. A PR that regresses quality past the acceptable threshold does not merge. This is where most teams start building their first eval pipeline. Without the development-stage unit tests in place, the CI run carries too much load.
- Production monitoring: continuously. Sample 5–10% of real traffic, score it with an automated evaluator, and watch for drift. This is the only layer that catches changes that happen to you rather than changes you make. OpenAI updated GPT-4 Turbo's underlying model weights without changing the API model identifier multiple times in 2023 and 2024 — there were documented complaints in their developer forum. Input distributions shift as new user segments arrive. Neither shows up in any offline eval.
- Runtime guardrails: synchronous, inline. Not an evaluation system. A safety system. An evaluator scores output quality asynchronously, after the fact. A guardrail blocks a specific failure mode inline, with millisecond latency requirements. They look similar from the outside. They are not interchangeable. Building an async evaluator when you need an inline guardrail means harmful outputs reach users; building a synchronous guardrail when you need an async evaluator means unacceptable p99 latency.
Evaluation methods
- Reference-based metrics compare model output to a known correct answer. BLEU and ROUGE measure n-gram overlap; exact match checks string equality. Use them for classification, structured extraction, slot filling — any task where valid output variation is minimal. Don't use them for open-ended generation. A summarizer that produces a demonstrably better summary than the reference answer gets penalized by ROUGE. The metric is doing exactly what it's designed to do. It's just the wrong tool for the job.
- LLM-as-a-judge uses a capable model to score outputs against a rubric. It scales without human review and handles open-ended tasks. Three failure modes to control for: position bias (Zheng et al., in their 2023 MT-Bench paper, found that swapping the order of two candidate responses shifted GPT-4's preference rating by more than 10% even when the responses were identical), verbosity bias (longer outputs score higher regardless of content), and self-preference (a judge from the same model family advantages its family's outputs in pairwise comparisons). Jury-of-judges setups — three independent judges, majority verdict — reduce all three biases and cost three times as much. Whether that tradeoff is worth it depends on how much a false positive in your eval costs versus a false negative in production.
- Human evaluation is the only method that establishes ground truth. Automated metrics and LLM judges measure quality relative to a proxy. Human raters determine whether the output is actually good. The cost means you cannot run this continuously — but the use case is not continuous scoring. The use case is producing the 30–50 labeled examples that calibrate your judge, and producing held-out test examples that confirm the calibration is holding over time.
The human alignment problem
Automated evaluation requires someone to decide what "good" means. Most teams treat this as a solved problem: write a rubric, hand it to the judge, ship it. It isn't solved.
Criteria don't emerge from rubric design. They emerge from grading. The first version of any rubric is wrong in ways you can't predict until you watch it fail on real examples.
The setup that works: one domain expert — someone who owns the product and understands the task — grades 30 to 50 examples with binary pass/fail verdicts and written critiques for failures. Not a committee. Committees produce criteria drift. Different annotators weight dimensions differently, and the resulting labels reflect who graded each example, not whether the output was actually good.
Use those 30 to 50 labeled examples to build and iterate the judge prompt. Measure precision and recall per class, not overall agreement rate. Agreement rate misleads on imbalanced datasets: a judge that stamps everything "pass" achieves 90% agreement on a dataset where 10% of outputs should fail.
Skip 1-to-5 Likert scales. They produce low-variance data (everything clusters between 3 and 4), force the judge to make distinctions it can't reliably make, and convert poorly into actionable feedback. Binary pass/fail with a written critique for failures generates better calibration data and forces the judge to commit.
The target: a judge whose scores match the domain expert's verdicts at a Pearson correlation above 0.7. Below that, you're measuring something — you just don't know if it correlates with whether users experience the system as working.
Offline vs. online evaluation
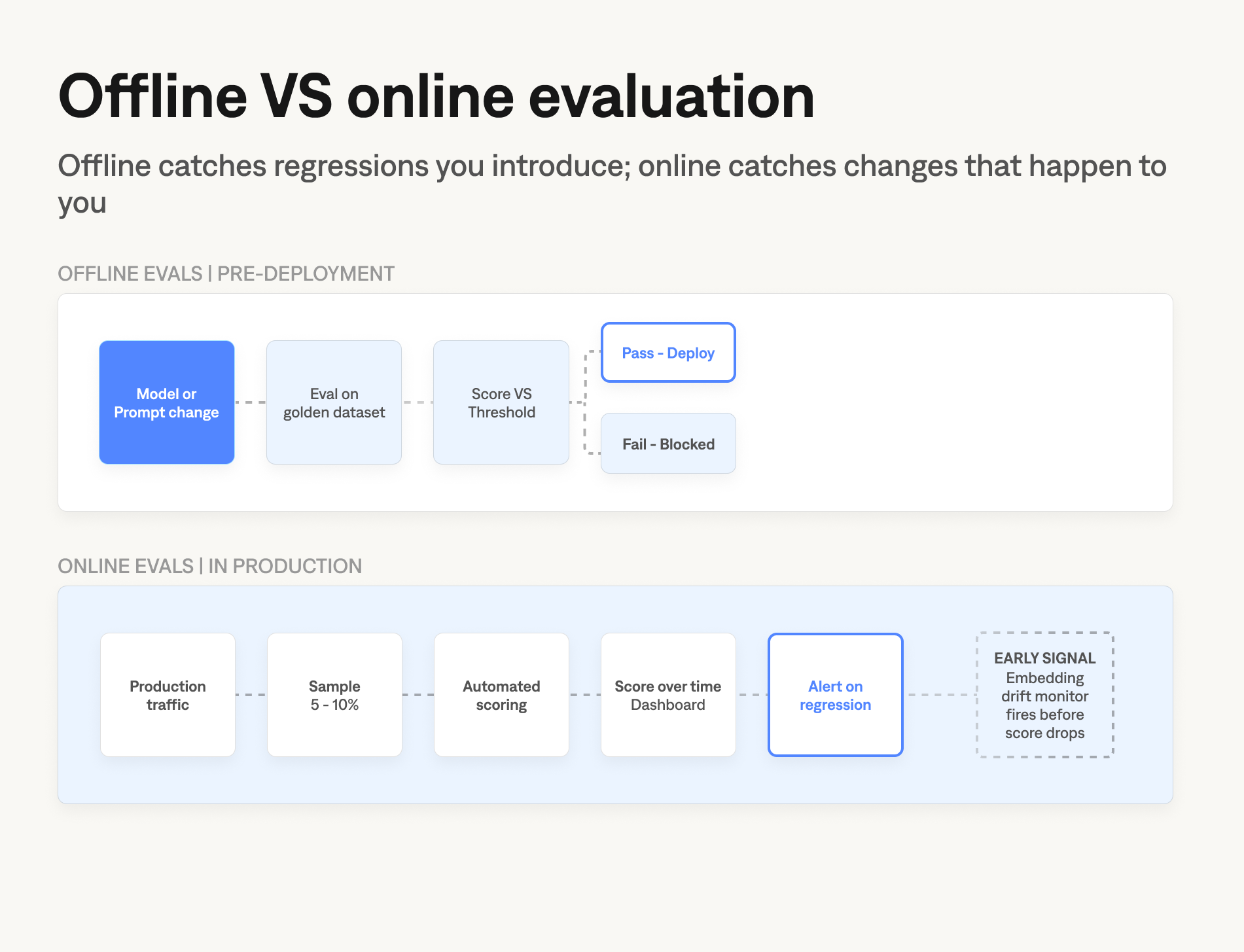
Offline evaluation happens before deployment. You test a fixed dataset against a specific model version or prompt — a controlled comparison where you hold everything constant except the variable under test. This is how you catch regressions before they reach users.
Online evaluation happens in production. You sample real user requests, score them with an automated method, and monitor for quality drift over time.
Both are necessary. Offline catches regressions you introduce. Online catches changes that happen to you: model provider updates without a version increment, input distribution shifts as new users find your product, new behavior patterns you didn't anticipate when you built your test set.
Embedding-based drift detection extends online monitoring further. By tracking the distribution of input embeddings over time, you can detect when the system is receiving queries meaningfully different from your golden dataset coverage — before failure rates climb. The distribution shift is the early signal; the score drop is the confirmation you should have acted on earlier.
Traces: the prerequisite nobody mentions first
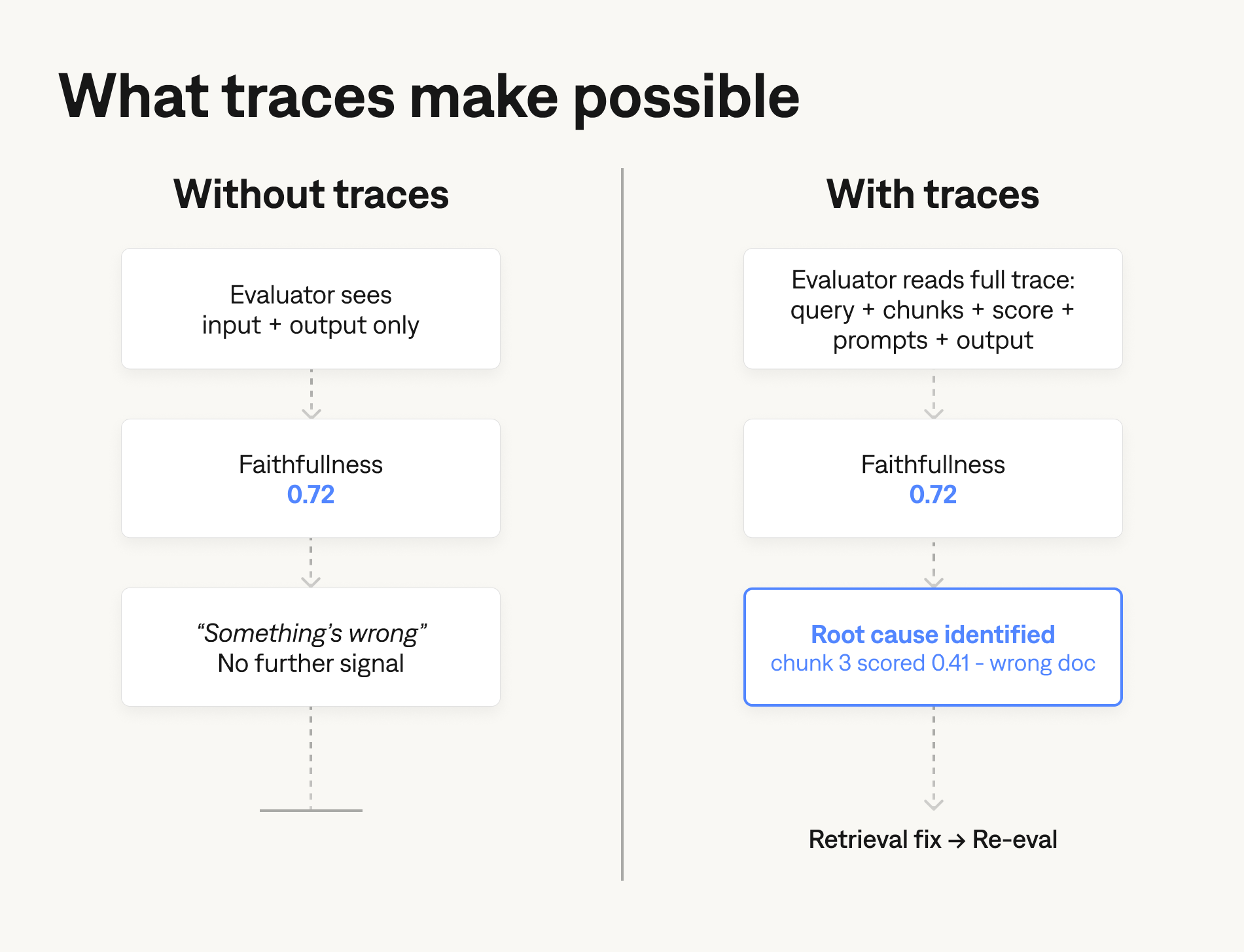
Evaluation methods operate on inputs and outputs. In production, those two things are not the full picture.
A trace records everything your system did to produce a response: the user query, the retrieved documents with relevance scores and source identifiers, any tool calls with their arguments and results, the assembled prompt sent to the model, and the model's response. For agent systems, the trace includes every step in the reasoning chain, not just the final output.
Without traces, you can see that 7% of outputs fail a faithfulness check. You cannot determine whether retrieval pulled irrelevant documents, whether the model ignored correct documents, or whether the query was too ambiguous for any retrieved context to help. The failure is visible. The cause is invisible.
Implement structured tracing before building any eval pipeline. The schema matters: retrieval scores, chunk sources, tool call arguments, and model latency need to be queryable independently. "We have logs" and "we have traces" are not the same thing. A log file you cannot filter by retrieval score does not help you diagnose a faithfulness failure.
Building a golden dataset

Every evaluation method needs data to run ag
ainst. The dataset is usually the bottleneck, not the method.
For offline evaluation, you need a golden dataset: inputs with known-correct or human-rated outputs that represent the actual tasks your application handles. Fifty examples detects large regressions. 200 examples gives statistical confidence on smaller differences — a 3 to 5% quality change. More than 500 is diminishing returns unless your application has highly varied sub-tasks that need separate coverage.
Where the dataset comes from matters more than its size. Datasets built from documentation or synthetic generation are too clean. They miss the edge cases, ambiguous queries, and adversarial inputs that surface once real users interact with the system. The most effective golden datasets combine three sources: human-crafted examples covering known edge cases, real production samples with PII removed, and synthetic expansions for underrepresented scenarios.
The methodological direction matters too. Top-down design — picking a metric and building a dataset to measure it — produces high scores against the metric and surprising failures in production. Bottom-up failure analysis — collecting real failures first, then designing the metric to catch them — produces evals that predict what actually breaks. Start with failures you've already seen, not failures you've imagined.
Calibrating the judge
This is where most evaluation setups break down. Getting here is the straightforward part. Getting here and having the judge scores mean something is the actual work.
Criteria don't emerge from rubric design. They emerge from grading. The first version of any rubric is wrong in ways you cannot predict until you watch it fail on real examples — outputs where two reasonable people applying the same rubric would grade differently, or outputs the rubric simply doesn't cover.
- One domain expert. Not a committee. Have the person who owns the product and understands the task grade 30–50 examples with binary pass/fail verdicts and written critiques for every failure. Not four people splitting the work. Committees produce criteria drift: different annotators weight dimensions differently, and the resulting labels reflect which annotator graded which example rather than whether the output was actually good. A 50-example calibration set labeled by four people with different quality models is noise with high confidence intervals.
- Binary pass/fail, not a 1-to-5 scale. Likert scales produce low-variance data in practice — scores cluster between 3.2 and 3.8, which is statistically equivalent to a coin flip across most of the range. They force the judge to make distinctions it cannot reliably make, and they convert poorly into actionable feedback. Binary pass/fail with a written critique for failures generates better calibration data and forces a commitment. If you inherit a Likert system, convert the labels to binary (pass = 4+, fail = 3 or below) before using them to calibrate anything.
Build the judge prompt iteratively against those 30–50 labeled examples. Measure precision and recall per class — not overall agreement rate. Agreement rate misleads on imbalanced datasets: a judge that stamps every output "pass" achieves 90% agreement on a dataset where 10% of outputs should fail. That judge is useless and will tell you it's 90% accurate.
Target a Pearson correlation above 0.7 between the judge's scores and the domain expert's verdicts. Below that threshold, you are measuring something — you just don't know if it correlates with whether users experience the product as working.
Building a pipeline that runs

The methods above work in isolation. They become useful only when they run automatically on every change. An eval pipeline that requires a manual trigger is an eval pipeline that won't run when it matters.
Three levels, each with different cost and cadence. Level one is unit tests: milliseconds, run on every commit, catch obvious breakage. Level two is human-plus-model evaluation: run against the golden dataset on every PR, catch quality regression. Level three is A/B testing: production traffic, meaningful sample sizes, only worth building once the product is mature and the earlier levels are stable. Teams that try to start at level two or three without level one skip the fast feedback loop that makes the slower levels tractable.
Within level two, four components make the pipeline work:
- Dataset version control. Your evaluation dataset is as important as your code. Version it, require code review on changes, and treat deletions or modifications to ground truth as production risk. Adding easier examples to make scores look better is a real and common failure mode.
- Evaluation harness. The code that runs each example through your model and evaluator. Consistency matters: same judge model, same rubric, same temperature settings across runs. A harness that changes between runs produces scores you can't compare.
- Acceptable fail rates, not binary thresholds. A hard threshold — scores above X ship, below X don't — creates false alarms and gets disabled. A more durable design: acceptable fail rates per failure category. A 3% hallucination rate on general queries might be tolerable; 8% is not. Safety failures at any rate block the deploy. Different failure modes warrant different tolerances.
- Regression tracking. Every eval run result stored with timestamps, so you can answer "when did this start failing?" A dashboard showing only the current score tells you nothing about causation.
Platforms like Galtea support specification-driven evaluation, where criteria derive from formal product specifications rather than ad hoc rubric design. This matters when you're managing multiple product versions or need evaluation results to map to documented requirements.
The benchmark trap
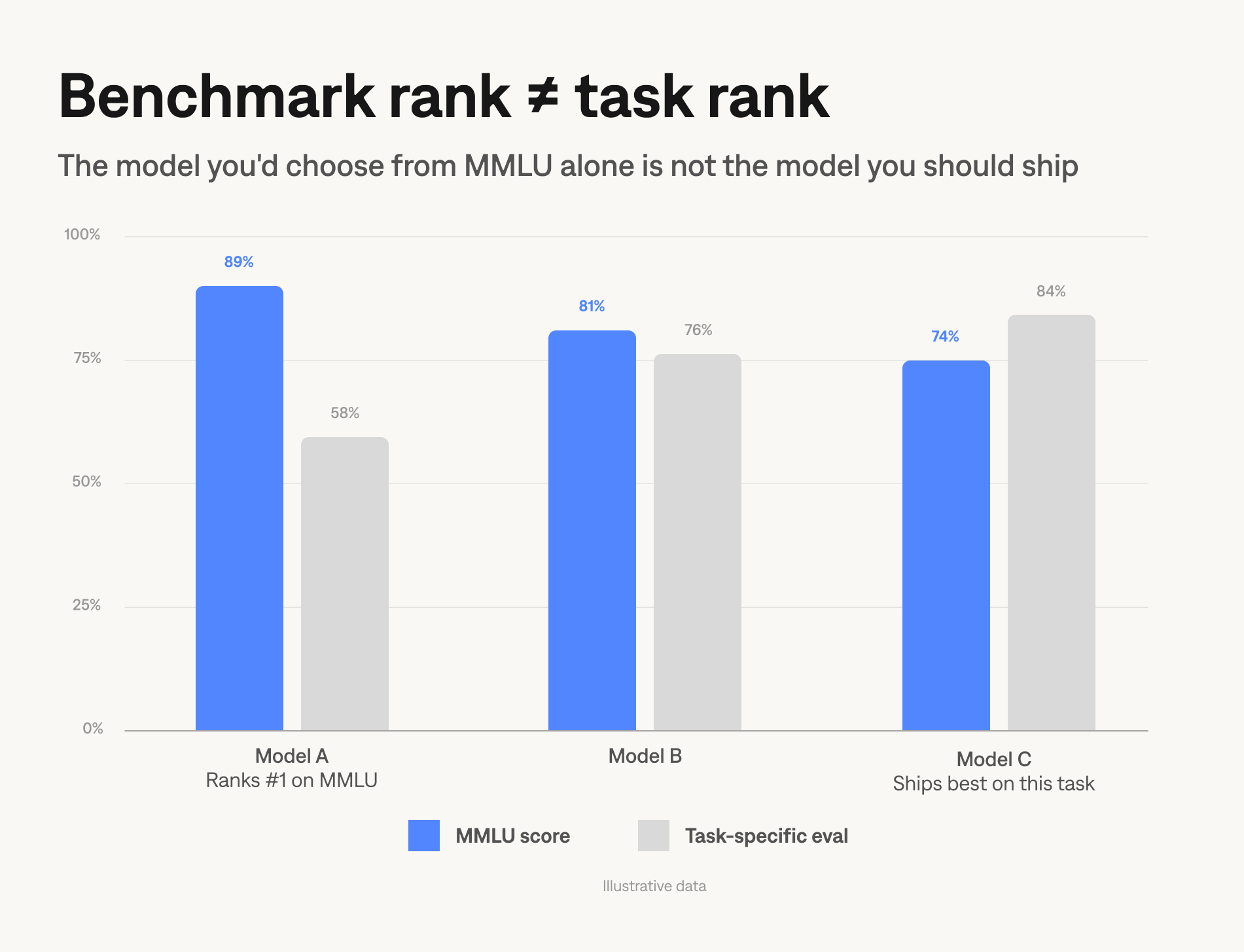
MMLU, HumanEval, HellaSwag — the standard benchmarks appear in every model release announcement and predict almost nothing about whether a model will perform well in a specific application.
The benchmarks are not poorly designed. MMLU measures broad factual reasoning. HumanEval measures code generation on self-contained problems. These are real capabilities. The problem is treating high scores on them as a proxy for "this model will work well in my RAG pipeline" or "this model will produce safe outputs for my specific user population."
Benchmark contamination makes this worse. The Allen Institute for AI's 2023 contamination study found that test items from MMLU and similar benchmarks had been included in multiple model training corpora (usually through data pipeline accidents — web crawls that pulled pages hosting the test questions). Contaminated models show benchmark gains that don't generalize to held-out tasks. A model ranking second on MMLU may have encountered MMLU during training. The score is partly a measure of benchmark exposure, not solely of capability.
Use benchmarks once, at the start of model selection, to eliminate obvious bottom-half candidates. A custom eval set of 100 examples from your actual use case, graded by your team, tells you more about which model to deploy.
The mistakes that make evaluations useless
- Optimizing the metric instead of the task. When eval scores become a team metric, prompt engineers optimize the eval set rather than improving actual output quality. Holding out a hidden test set that doesn't participate in development is the standard protection against this.
- Running evaluations only after something breaks. Retrospective evaluation confirms something went wrong. Running evals on every change tells you what changed and when.
- Trusting Likert-scale scores without calibration. A judge that scores everything between 3 and 4 out of 5 is averaging, not evaluating. Convert to binary, calibrate against domain expert verdicts, verify Pearson r > 0.7.
- Using off-the-shelf judges without calibrating them. Pre-built eval libraries ship generic rubrics designed to work across tasks. They produce confidently wrong scores on specialized applications. The calibration process is not optional.
- Conflating model quality with application quality. A better base model is not always a better application. A model upgrade can improve average output quality while introducing edge-case behavior that breaks safety filters or changes tone in ways that violate the product's behavioral requirements. Evaluate the system. Not just the model component.



