LLM as a Judge: The Complete Guide
LLM-as-a-judge is the practice of using one language model to evaluate another model’s outputs against a rubric, making scalable AI evaluation practical for chatbots, RAG systems, and agents. The article explains the three core judging modes, where LLM judges work well, where they fail, how to write reliable rubrics, and why calibration against a labelled gold set is mandatory before production use.


TL;DR — LLM as a judge is the practice of using a language model to score another model's output against a written rubric, in place of (or alongside) human raters. The MT-Bench paper from Zheng et al. (2023) showed that GPT-4 agrees with human experts at roughly 80%, on par with how often two humans agree with each other on the same task. That result is what made the technique the default for evaluating chatbots, RAG pipelines, and agents at scale. It is also what lets the technique fail silently: a generic judge can match the average human while missing every hallucination in your test set. Use single-answer scoring with an explicit rubric for production evaluation, pairwise comparison for ranking model versions, and never trust a judge you have not measured against a labelled gold set.
This piece is for engineers who already build evaluations and want a defensible answer to "should we use an LLM judge here, and if so, how?" If you have never written an eval before, start with the MT-Bench paper, then come back.
What "LLM as a judge" actually means
An LLM judge is a model called with a prompt that asks it to evaluate something, usually another model's response. It returns a score, a label, or a preference. That is the entire architecture. Everything interesting is in the prompt, the rubric, and how you measure whether the judge's verdicts agree with reality.
The pattern was named in Zheng et al.'s "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena". Before that paper, people were already using LLMs to grade other LLMs (OpenAI's evals repo had been doing it since GPT-3.5), but MT-Bench was the work that put numbers on it. They graded 80 multi-turn questions across writing, reasoning, math, coding, knowledge, and roleplay, using GPT-4 as the judge and pairs of human experts as the ground truth. Agreement between GPT-4 and humans landed in the same range as agreement between two humans. The technique was real.
The reason it caught on is operational, not philosophical. A human-only evaluation pipeline scales badly. Three raters, 200 examples, and a multi-criteria rubric is a week of work. Substitute an LLM judge and the same eval runs in 12 minutes for $4. The tradeoff is that the judge brings its own biases, and unlike human raters, those biases are systematic.
How an LLM judge scores outputs

There are three scoring modes, and the choice between them changes what your evaluation can and cannot tell you.
- Pairwise comparison asks the judge to pick which of two responses is better. This is what Chatbot Arena is built on, and it is the most reliable mode in the MT-Bench results, because relative judgments are easier than absolute ones. Use pairwise when you are A/B testing two model versions or two prompts. Do not use it when you need an absolute quality threshold, because pairwise scores have no ground floor: response B can win every comparison and still be unusable.
- Single-answer grading with a rubric asks the judge to score one response against an explicit standard. This is the mode you want in production, because every response gets a score on the same axis, and you can set deployment gates around it ("ship if faithfulness recall stays above 0.85 on the canary set"). Pick the lowest-precision scale that captures the distinction you care about: binary pass/fail when the question is "did the model violate the rubric, yes or no," a three-point scale (fail / partial / pass) when degrees of failure matter for triage, and only go to 1-to-5 or 1-to-10 if you genuinely need the resolution and have the gold-set data to validate that the judge can use it. Fine-grained scales invite the judge to invent distinctions it cannot defend, and the resulting noise eats the signal you wanted to measure. Rubric quality matters more than scale choice. A vague rubric ("rate the helpfulness from 1 to 5") gives you a number with no information content. A claim-level rubric ("score 0 if any factual claim is not directly supported by the retrieved passage") gives you a number you can act on. Rubrics are also unstable over time; Shankar et al. (2024) documented that human evaluators routinely revise their criteria after seeing model outputs, a phenomenon they call criteria drift, which is why a rubric written upfront should never be treated as final.
- Reference-based grading gives the judge a known-good answer and asks how close the candidate is to it. This is the closest analogue to traditional NLP metrics like BLEU and ROUGE, but with semantics rather than n-gram overlap. It works well for tasks with constrained outputs (translation, summarization against a gold summary, structured data extraction). It collapses on open-ended tasks, because there are usually many acceptable answers and the judge will penalise responses that are good but different.
In practice most production setups use single-answer grading per criterion (faithfulness, relevance, and format compliance) and use pairwise comparison only during development to choose between candidate prompts.
When an LLM judge is the right tool
An LLM judge works well on tasks where the judgment is essentially a reading-comprehension problem against a clearly stated rubric. "Does this response contain any factual claim not supported by the retrieved context?" is a reading-comprehension question. So is "Does this response refuse to answer in the cases the spec requires it to refuse?" The judge model has to extract the claim, locate the supporting passage (or note its absence), and return a verdict. Frontier models do this well.
It works less well on tasks that require the judge to know things the prompt cannot encode. "Is this response funny?" is a question every model will answer, but the answers will reflect the judge's priors, not your readers'. "Is this code idiomatic Rust?" requires the judge to have absorbed the same conventions as your team, which it probably has not. For these tasks, treat the judge as one signal among several rather than as ground truth.
It actively hurts on tasks where the cost of a missed failure is high and the failure pattern is rare. A judge that catches 80% of hallucinations sounds fine until you are deploying a medical-information chatbot where the remaining 20% is the regulatory exposure. In those cases, the judge is a triage filter (it cuts the volume of cases human reviewers see), not the final word.
A worked example: a faithfulness judge in 40 lines
The simplest useful judge is a single-answer faithfulness rubric for a RAG response. Here is a runnable version using the OpenAI Python SDK (tested against openai==1.54.3 and gpt-4o-2024-11-20):
Three things worth noting about this prompt that a generic version usually misses. The judge is told to enumerate claims before evaluating them, which is chain-of-thought prompting applied to evaluation: the explicit reasoning step forces a claim-level check rather than a vibes-level check, and Wei et al. (2022) showed that this kind of step-by-step structure consistently improves performance on classification and reasoning tasks. Truncated context is explicitly handled, because retrieval pipelines truncate at chunk boundaries and the judge will otherwise treat partial sentences as full support. Temperature is zero, because non-zero temperature on a binary classification task introduces variance you cannot interpret.
This is enough to run, not enough to ship. The next two sections cover the parts that turn a working example into a deployable judge: getting the prompt right, then measuring whether it actually agrees with humans.
Writing the judge prompt and rubric

The judge prompt is where most of the gains in an LLM-as-a-judge setup actually come from. The model is fixed by your provider, the scoring scale is fixed by your rubric design, and the gold set is fixed by your domain. The prompt is the only piece you can iterate on cheaply, and it is the piece that distinguishes a judge that scores 0.40 alignment from one that scores 0.75 against the same labels.
A working judge prompt has four elements. A definition of the criterion in the words your domain uses, not generic ML vocabulary ("faithful to the retrieved context" is a domain definition; "high quality" is not). An explicit reasoning structure that tells the judge to enumerate the discrete claims, conditions, or tool calls before scoring (this is chain-of-thought, and it improves performance on classification tasks across the board). A scoring rule that maps the reasoning result onto the scale, like "if any enumerated claim is not directly supported by the retrieved context, score 0," not "use your judgment." And a handling clause for the edge cases that show up in production: truncated context, empty retrievals, partial answers, refusals.
What you should not put in the prompt is a long list of "make sure your answer is helpful, honest, and harmless." Generic instructions get ignored. Specific claim-level rules get followed. The other thing to avoid is over-specifying the format of the verdict; if the model has to produce a long structured rationale before its score, you are paying for tokens you will not read.
The biases that make naive judges unreliable
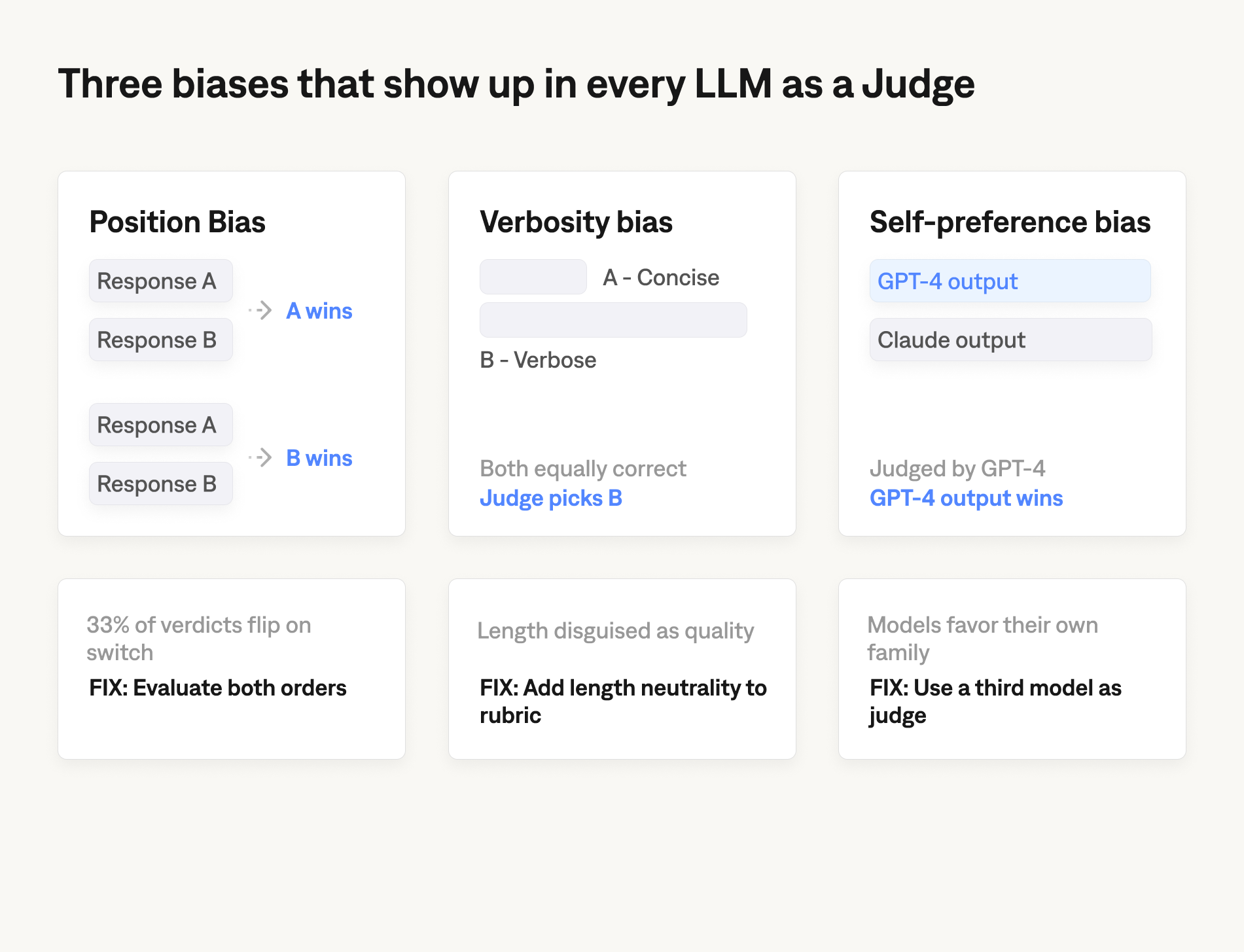
Three biases show up consistently enough that they have names. All three were documented in MT-Bench and have been reproduced in subsequent work; the magnitudes vary by model and task, so treat the figures below as illustrative.
- Position bias is the tendency to favour whichever response appears first (or sometimes last) in a pairwise comparison. In the original MT-Bench measurements, GPT-4 changed its preferred answer when the order was swapped on roughly a third of cases. The fix is to evaluate every comparison in both orders and only count cases where the verdict is consistent. It doubles your inference cost and is not optional.
- Verbosity bias is the tendency to prefer longer responses. Newer judges are less susceptible than the original GPT-4, but the bias has not gone away, and it interacts badly with single-answer rubrics that do not include length as a criterion. If your rubric does not say "concise responses score equal to or better than verbose ones at equivalent correctness," your judge is implicitly optimising for length. The mitigation is to put length neutrality into the rubric explicitly.
- Self-preference bias is the tendency for a judge to favour outputs from the same model family it belongs to. The size of this effect is contested (some replications find it small, others find it large), but it is large enough that you should not use Model A as the judge in an A-versus-B comparison if either A or B is Model A. Use a third model as judge, or use human raters for that specific comparison.
There are more (sentiment bias, sycophancy bias, length-priors that interact with rubric formatting), but these three account for most of the production failures we see in practice. Detecting them in your own gold set is what calibration is for.
Calibrating the judge against a labelled gold set
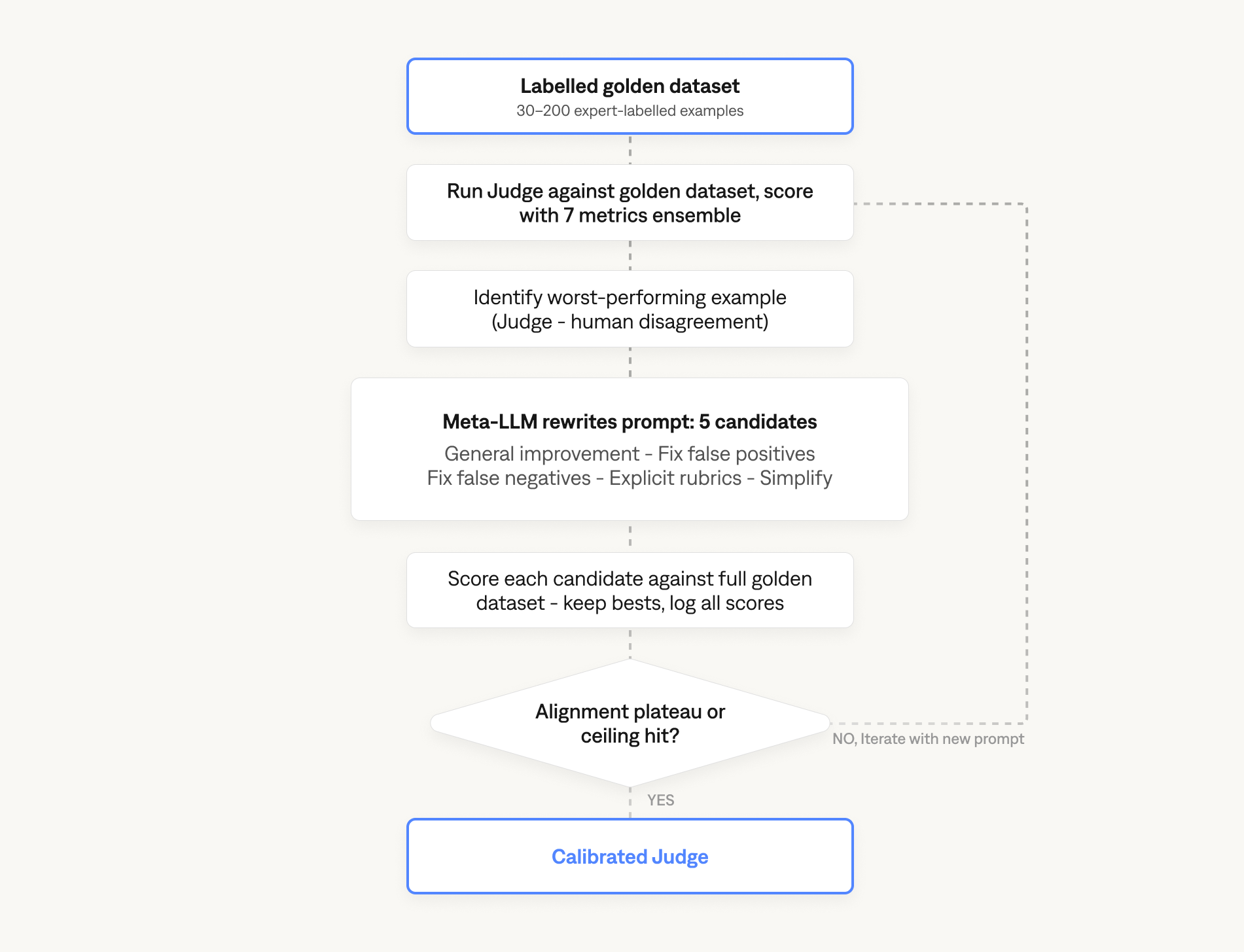
A judge prompt that looks reasonable on three examples will fail in production. The way to find out before deployment is calibration: run the judge against a labelled gold set, measure the gap between its verdicts and the human labels, and iterate the prompt until the gap closes.
The minimum viable calibration loop has three inputs. A gold set of 30 to 200 examples drawn from the actual evaluation distribution, labelled by domain experts (not generalist annotators; domain knowledge matters here, and the difference is large). A baseline run that records the full ensemble of accuracy, precision, recall, F1, Pearson correlation, Spearman correlation, and Cohen's Kappa, not just one of them. And an optimization step that rewrites the prompt against the worst-performing examples, using a meta-LLM as the optimizer (the OPRO pattern from Yang et al. 2023). The loop iterates until alignment plateaus, which in practice is between five and ten iterations.
Why all seven metrics, not just accuracy: aggregate accuracy hides per-class recall. A judge with 0.9 accuracy and 0.1 Cohen's Kappa is essentially guessing; the same judge would produce similar accuracy on a shuffled dataset. A judge with 0.7 accuracy and 0.6 Kappa is reasoning. Reporting accuracy alone is the most common mistake teams make when they think they have a working judge.
For the seven-metric ensemble in detail, the OPRO loop, the cost-versus-alignment analysis, and a real production case where calibration moved a generic GPT-4.1 judge from 0.40 to 0.75 alignment using nine human annotations, see How to optimize your LLM Judge for AI evaluations.
Building the gold set
Calibration depends on a gold set, and gold sets do not exist by default. Building one is the prerequisite step that determines whether everything downstream is measuring something real or measuring noise.
A gold set is a collection of input-output pairs labelled by domain experts with the verdict you want the judge to produce. Three properties make a gold set load-bearing for evaluation. It has to be drawn from the actual evaluation distribution: real queries, real retrieved contexts, real agent responses, not synthetic examples that look plausible to whoever wrote the dataset. The failure classes have to be represented; a gold set of 100 examples that are all faithful tells you nothing about whether the judge catches unfaithfulness, which is the only failure that matters. And inter-rater agreement on the gold set has to be measured before it gets used; if two domain experts disagree on more than 20% of labels, the rubric is ambiguous, and calibration will optimize against noise rather than against the failure modes.
Generating the queries and synthetic-but-realistic answers for a gold set is its own engineering problem. Several frameworks now exist to do this from your source documents, and the differences between them affect what kinds of failures the resulting gold set surfaces. For a head-to-head test of six question-and-answer generation frameworks against the same source documents, see Golden datasets for LLM evaluation: six Q&A frameworks tested.
Judge-human agreement is task-specific
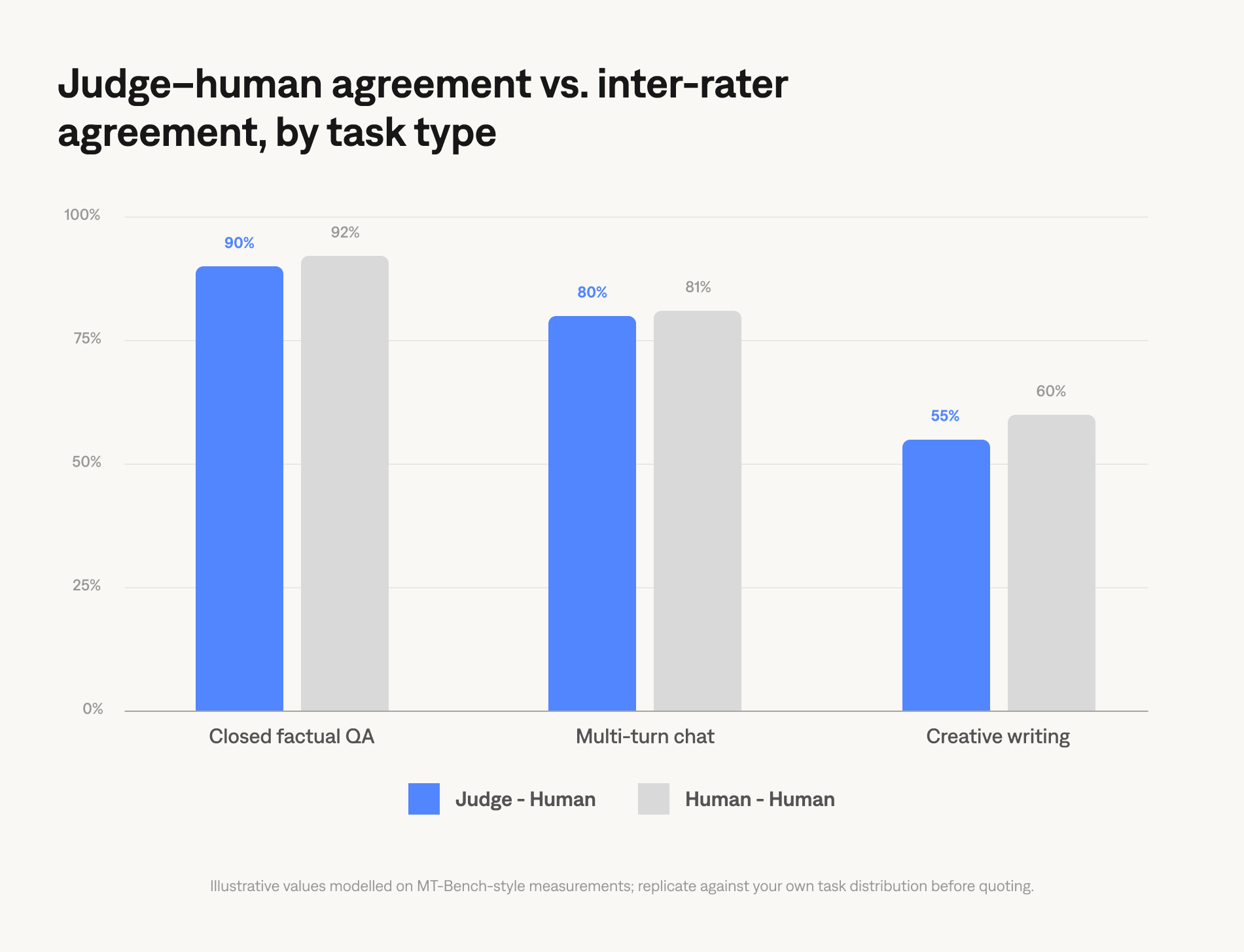
The figure most people remember from MT-Bench is "around 80%," but that number hides three things worth knowing.
The first is that 80% is the agreement on the type of task MT-Bench measured (multi-turn open-ended chat). Agreement is higher on closed tasks (factual QA, code with deterministic output checks) and lower on tasks where humans themselves disagree (creative writing, opinion, and humor). The judge cannot exceed inter-rater agreement on the underlying task; if two human experts agree only 65% of the time on whether a response is helpful, no judge will hit 80%.
The second is that agreement is not the same as alignment. A judge can score 80% raw accuracy by getting most of the easy cases right (faithful responses identified as faithful) while missing every instance of the failure class that actually matters (unfaithful responses passed through as faithful). The aggregate number flatters the judge; the per-class recall is what tells you whether to ship it. The calibration section above is what fixes this: measure both, fix the prompt against the failures, repeat.
The third is that agreement metrics depend on the metric. Reporting raw accuracy on an imbalanced gold set (mostly passing examples, few failures) flatters the judge. Reporting Cohen's Kappa, which adjusts for chance agreement, is harder to fake. A judge with 0.9 accuracy and 0.1 Kappa is essentially guessing. Pearson correlation is useful for continuous scores; Spearman holds up better if you only trust the ranking and not the absolute values.
For production pipelines, the floor is: measure on a labelled gold set, report at least accuracy plus Cohen's Kappa, and treat any single-metric claim with suspicion.
The decision of when to use an LLM judge alone, when to use it as a triage filter with humans on the flagged subset, and when to skip the judge and use humans-only depends on three variables: the cost of a missed failure, the volume of evaluations, and the rate at which the evaluation distribution drifts.
From example to production: wiring the judge in
The 40-line example earlier in this article is enough to grade one response in a Python REPL. Putting a judge in front of every production response (or running it on every pull request in CI) is a different engineering problem.
The bits that come up at scale are unsexy. Batching requests so judge inference does not dominate end-to-end latency. Retry handling for the cases where the judge returns malformed JSON, exceeds rate limits, or times out. Structured logging of verdicts and reasoning traces so you can diagnose later why a specific case was flagged. Regression detection that fires when alignment on the canary gold set drops between deploys. Versioning of judge prompts the same way you version the application code, so you can attribute alignment changes to specific prompt edits. And integration with your CI system so a judge run is part of the deploy gate rather than a manual check someone forgets to do under time pressure.
None of these are intellectually hard. All of them are work, and the order in which you implement them affects which production failures you hit first. The mistake most teams make is shipping the prompt-and-eval loop without versioning, then losing the ability to attribute regressions when alignment shifts.
When NOT to use an LLM judge
Three situations where you should not reach for a judge, and where teams routinely do anyway.
When the task has a deterministic correctness check, do not use a judge. SQL query equivalence, JSON schema validation, regex matching, exact-string comparison, and tool-call argument matching are all solved problems. An LLM judge wrapping any of these adds latency, cost, and a non-zero chance of being wrong about something that has a definitive answer. Run the deterministic check, fail fast on mismatch, and only call the judge for the parts that genuinely require natural-language reasoning.
When you have not built a labelled gold set, do not use a judge in production. The judge gives you a number. Without ground truth, you cannot tell whether the number means anything. Teams ship judges that score 4.2 out of 5 on average and use that as a deployment signal, not realising that the same judge would score a randomized baseline at 4.0. The gold set does not need to be enormous (30 well-chosen examples beats 300 sloppy ones), but it has to exist.
When the cost of a missed failure exceeds the cost of human review, do not use a judge as the final gate. Use it as a triage filter that cuts the volume of cases humans review. A judge that catches 80% of failures lets human reviewers handle five times their previous throughput; that is a real win. A judge deployed without a human in the loop in a regulated domain is a different decision, and one that should be made explicitly with the legal and compliance functions involved, not implicitly because the judge happened to score high on a dev-set.
The judge is a tool, not a verdict. It earns its place by catching the failures you would otherwise ship. It loses its place the moment you stop measuring whether it still does.
Galtea is an AI evaluation platform that enables developers, QA engineers, product managers, and even domain experts to test their agents by generating hundreds of high-quality scenarios in under 2 minutes.
Build Reliable AI Evaluations with LLM Judges
See how to deploy calibrated LLM-as-a-judge workflows for RAG systems, agents, and production AI evaluations
