onJun 18, 2025

onJun 18, 2025
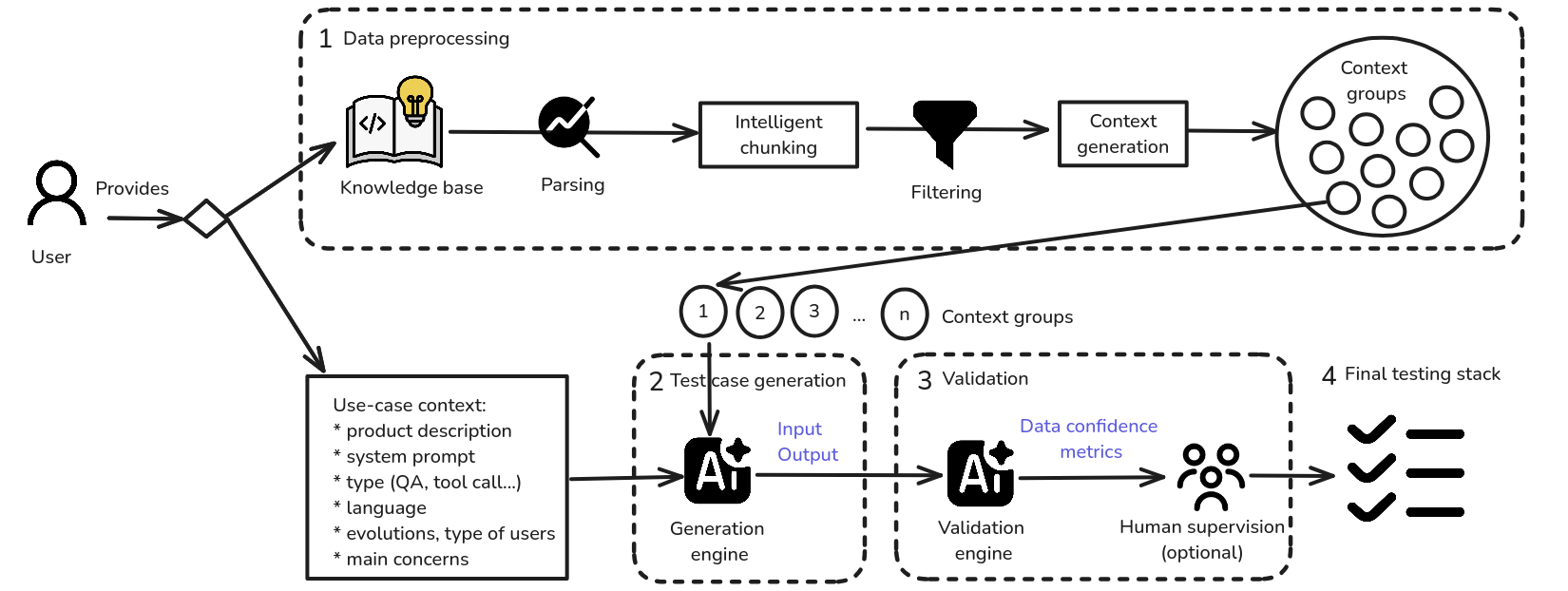
One of the most frequent questions we get at Galtea is: how can I create a solid set of test cases to evaluate my GenAI system? And it’s a very valid concern. Teams often end up launching products based on generative models without a robust evaluation strategy. It’s common to rely on loosely structured manual reviews which, while useful in the early stages, are neither scalable nor reliable in the medium term.
Why does this happen? Because building a testing stack is seen as a large, costly, and thankless investment. There’s always something more urgent: a feature to ship, a bug to fix, a demo to prepare. But the truth is that investing in testing before it becomes “necessary” is what separates a robust, maintainable system from one that breaks at the first sign of change.
The good news is: you don’t need to get everything right from the start. In fact, the best approach is to start “poorly”, but start, and iterate from there. In this blog post, we’ll walk you through how to approach test generation for your generative system in a progressive, efficient, and realistic way, and what methodologies we use at Galtea to help you get there.
Our first recommendation is to approach test creation as an iterative process. Instead of spending weeks building an exhaustive test suite that might not be relevant six months from now, start with these steps:
Once that foundation is in place, you can scale up. This is where the various testing methodologies we use at Galtea come into play. Let’s go through the main ones.
Below, we outline the main types of tests we recommend depending on the system’s complexity and level of customization.
One of the first types of testing we recommend to companies working with generative systems is red teaming. The goal here is clear: evaluate how the system responds to malicious, adversarial, or unexpected inputs. While red teaming originally came from offensive cybersecurity, in GenAI it has a broader scope, covering prompt injection, manipulative intents, toxic or biased content generation, attempts to extract sensitive data, or even out-of-scope questions (e.g., a legal copilot user asking who will win the next Champions League😅).
At Galtea, we’ve built and maintain an extensive, up-to-date database of thousands of attack examples, categorized by type and labeled for reuse. This database serves as the starting point for generating tests tailored to the specific context of each system.
The process begins with identifying the most relevant risks based on the product’s domain. For example, an HR assistant must be robust against gender or racial bias, while a legal assistant must avoid hallucinating nonexistent regulations or case law. From that prioritization, we select representative attack subsets and tailor them to the client’s use case, incorporating their language, UI, and common entities.

Once these cases are generated, they’re evaluated using metrics that quantify system safety and robustness. For example, we check whether offensive content was reproduced (toxicity level), whether the system resisted manipulative prompts (jailbreak resilience), whether systematic biases appear (bias detection), or whether it revealed restricted information (data leakage resilience). These metrics can be automated or used in human review cycles.
When evaluating generative systems that depend on external sources, either via retrieval (RAG) or tool usage, having a reliable reference output is critical: a gold standard. This is the ideal expected output given a specific input and the available information resources.
In RAG systems working with unstructured information, the goal is to check that the model properly understood the input, retrieved relevant context, and generated an accurate, coherent, and source-faithful response. This involves a complex pipeline. Raw documents (PDFs, HTML, DOCX, etc.) are parsed and split into informative fragments using smart chunking techniques. This isn’t trivial, poor segmentation can dilute information or add noise. At Galtea, we use hybrid strategies combining semantic segmentation and structural rules, such as detecting headings or topic changes.
Next comes filtering, and once relevant chunks are identified, they’re grouped by contextual affinity to form stronger retrieval units. Based on these, synthetic Q&A pairs are generated. The input simulates a real user query, while the output reflects the ideal system response given the available evidence. Each output includes a confidence score to indicate how well-supported it is by the source, helping calibrate thresholds or trigger human validation if needed.
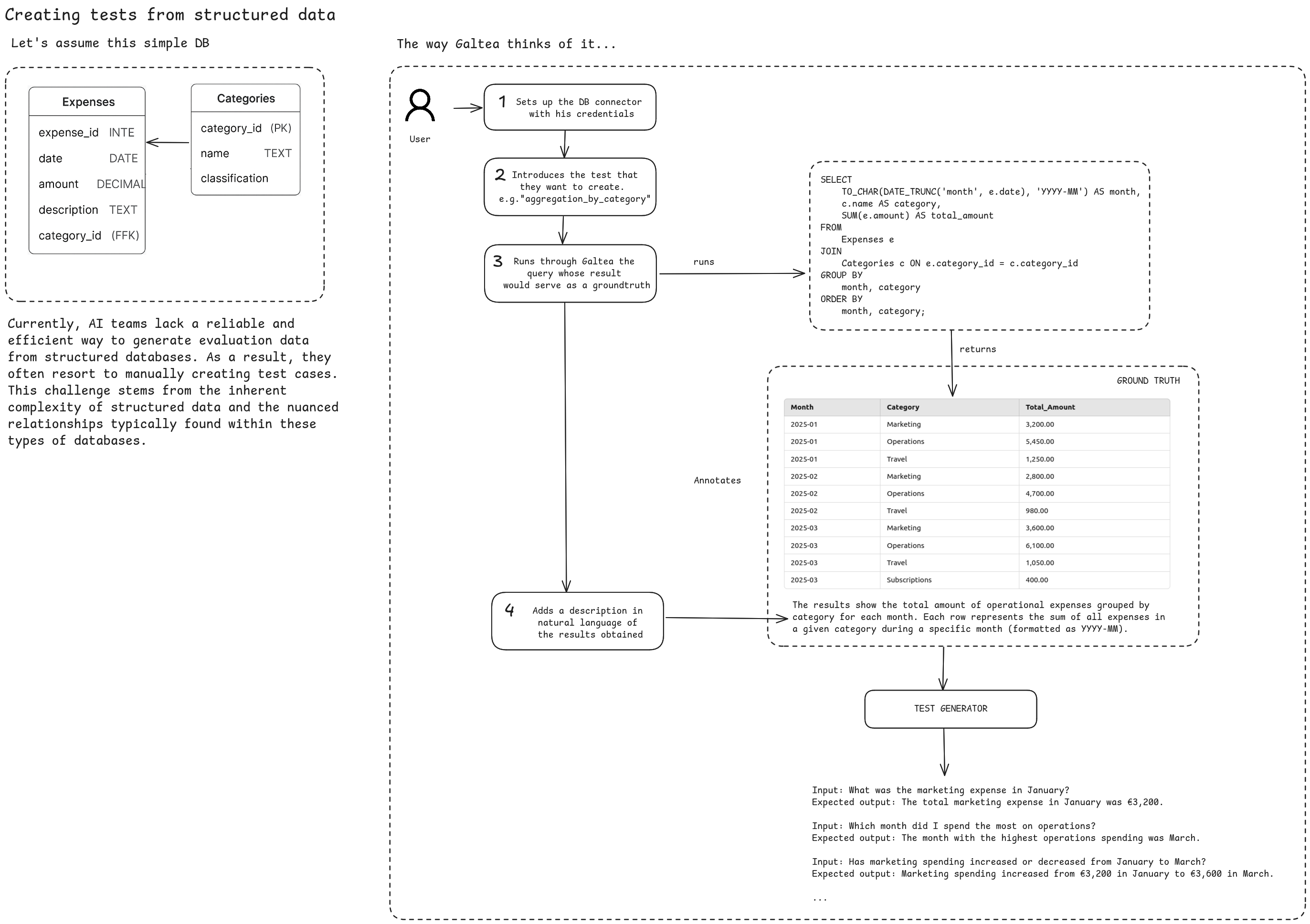
When the source is structured, like a relational database, the approach shifts. Evaluating GenAI systems that answer database questions presents different challenges. Even with accurate, organized data, logical complexity and inter-table relationships make test case generation difficult. At Galtea, we use a strategy that allows for reliable test creation without manually crafting each one.
The process starts with an intermediate SQL query that reflects the business logic being tested. This query returns a result table that serves as an objective reference or ground truth, validated by humans. A short natural language description is added to contextualize the result and enable understandable test generation.
From the annotated table, we generate natural language questions whose answers can be inferred directly from the data. Each input is translated into a new SQL query executed over the reference table, ensuring the expected output is correct and traceable. This covers reasoning patterns like comparisons, aggregations, min/max detection, time evolution, etc.
This approach shifts complexity to the query creation step, relieving the generative model from navigating complex schema relationships.
For systems using tool calling, the focus is on whether the model can use external tools effectively. First, you formally define the available tools, their APIs, and the tasks they handle. Then, you construct inputs that, under certain conditions, should trigger one or more specific tools. The expected output isn’t the generated text, but whether the correct action (e.g., an API call with proper parameters) was executed.
In both RAG and tool use cases, metrics go beyond “nice” or “believable” answers. They target deeper performance indicators: source fidelity, tool use correctness, relevance to the user’s goal, and data accuracy.
These tests are especially critical in domains where correctness outweighs fluency like legal, financial, or technical support applications.
Unit tests and one-shot evaluations have a clear limitation: they can’t assess how generative systems behave in real conversational scenarios, where context, memory, turn-taking, and long-horizon decision-making are key to success. This is where synthetic user generation comes in as an advanced methodology to simulate realistic multi-turn interactions using configurable user profiles and scenarios.
Galtea’s approach is modular, combining two key elements: user types and interaction scenarios. User types define behavior profiles with adjustable traits, such as expertise level, communication style, impatience, or decision preferences. These can be mixed to create archetypes like the expert user, the confused one, the undecided, the impatient, or the explorer. Each profile affects tone, pacing, and expectations throughout the conversation.
Scenarios define goal-oriented tasks, such as purchasing insurance, resolving a tech issue, or requesting a refund. These are procedurally generated from diverse sources, historical forms, FAQs, domain ontologies, or technical documentation. The result is a coherent simulation environment with context, constraints, and clearly defined success conditions. For example, a scenario might require the user to complete a reservation without errors, receive an email confirmation, or validate a specific condition via an external tool.
Once the scenario and user profile have been defined, a tester agent, i.e., a generative model simulating a synthetic user, interacts with the system under test. This agent operates based on structured prompts and orchestration logic, which guide it to exhibit specific behaviors, such as rephrasing questions when answers are ambiguous, experimenting with alternative strategies to accomplish a goal, or terminating the interaction upon reaching a predefined frustration limit. The system, in turn, must respond in real time with accuracy, adaptability, and efficiency.
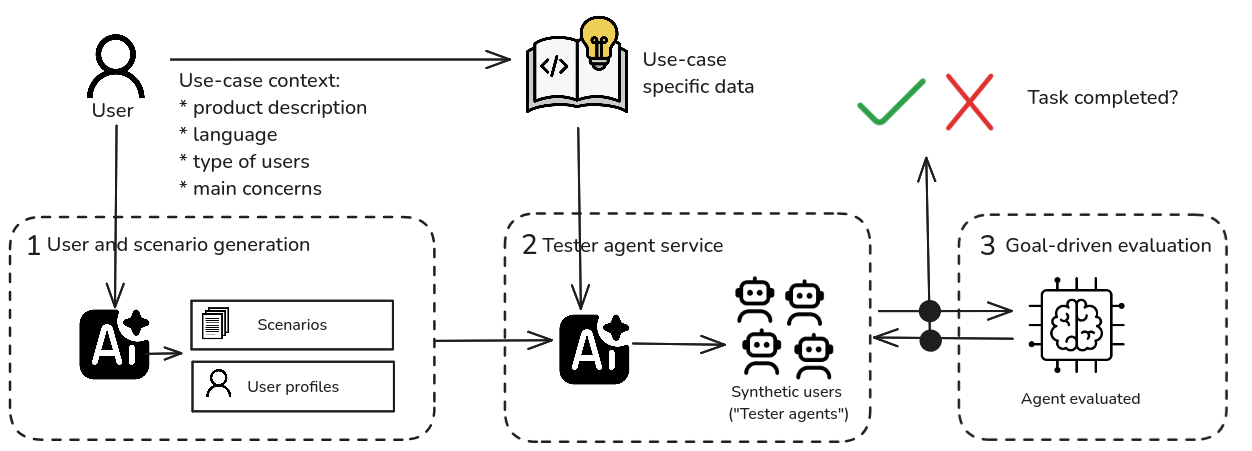
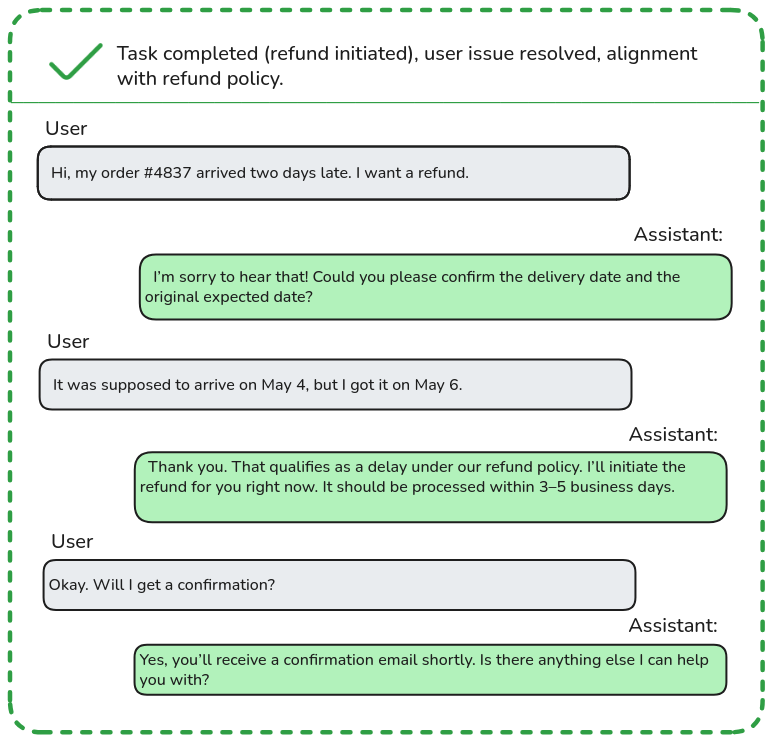
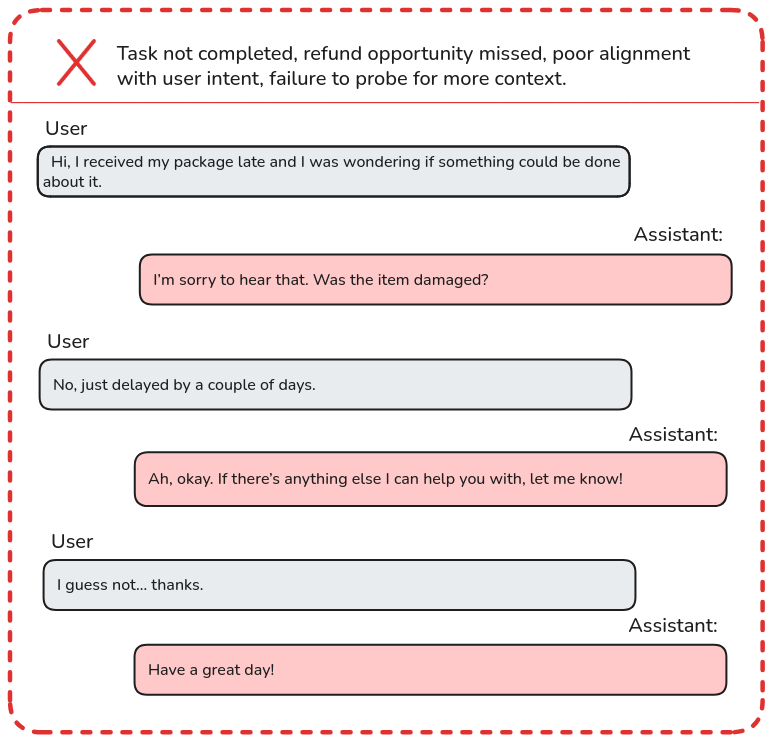
The interaction between the synthetic user and the system produces a conversational log, which is analyzed using goal-based metrics: whether the scenario was completed successfully, how many turns it took, whether there were behavioral deviations, inconsistencies, or conversation breakdowns. This offers a holistic view, not just of whether the system gives correct answers, but whether it can guide users toward successful outcomes across diverse situations.
This methodology enables large-scale, automated evaluation across hundreds of scenarios without requiring human intervention. It also facilitates regression testing, version comparison, and stress testing using edge-case user profiles. This approach is particularly valuable in applications where task success and user experience are paramount, such as virtual assistants, customer service bots, onboarding flows, and transactional agents.
Building a robust test suite doesn’t have to be an overwhelming task. You can start small, iterate intelligently, and scale in a controlled way. The key is to stop relying solely on human judgment and start trusting evaluation systems that are replicable, measurable, and tailored to your specific use case.
At Galtea, we help companies across industries build their GenAI testing stack without losing their minds. Whether it’s through red teaming, gold standard generation, or synthetic user simulations, our goal is to give you visibility, confidence, and control over your generative systems.
If you want to learn more, book a demo with us: Galtea Demo