onMay 20, 2025

onMay 20, 2025
Large Language Models (LLMs) are rapidly reshaping the way we build and interact with software, enabling powerful applications through natural language. But with this new capability comes a growing concern: how can we ensure these models behave safely in the face of unpredictable, adversarial inputs?
At Galtea, we believe that Red Teaming is essential not only to evaluate LLM safety, but also to proactively anticipate the ways these systems might fail. Our goal is to identify failure modes before they reach production, through a combination of curated datasets, automated analysis, and robust evaluation. In order to do that, we follow closely what is available from the research and open source community.
In short, we saw that there was a large variety of LLM safety datasets, and no clear categorization between different types of threats and attacks. Hence, we employed an unsupervised clustering algorithm to categorize different types of threats, document them, and further clean these categories for future use.
In this blog post, we walk through part of the process we’ve followed in improving our LLM Red Teaming pipeline, and publish our results to guide the rest of the community:
Below, we explain each step in more detail and share the insights we gained along the way.
The foundation of our red teaming pipeline began with the collection of high-risk prompts from a wide range of public datasets. We sourced content from PKU, SEAS, HarmfulQA, and several others*. These datasets include both adversarial and non-adversarial examples, covering a variety of real-world attack vectors targeting LLMs, such as prompt injections, jailbreaks, unethical advice, and harmful queries.
To keep track of the datasets and assess their usefulness, we registered the metadata of each dataset. There we included details like the dataset’s origin, license, structure, and type of adversarial behavior it focused on. Our goal was to gather as much diversity as possible.
*See the full dataset list and links in the table at the end of this document.
Once we had gathered all datasets, we initiated a comprehensive data cleaning and harmonization process to make them usable in a unified pipeline. Each dataset came in a different format, with its own column names and structure. To standardize them, we:
After all individual datasets were cleaned and transformed to match a common schema, we merged them into a single large, fully standardized, filtered dataset.
Once we had a clean and unified dataset of adversarial prompts, our next goal was to understand the different types of attack behaviors within it. To do that, we needed a way to compare prompts based on their meaning, not just keywords or exact wording.
To achieve this, we used a technique called sentence embeddings. Specifically, we passed each prompt through the model sentence-transformers/all-MiniLM-L6-v2, which converts any sentence into a vector of 384 dimensions. These dimensions represent the semantic meaning of the sentence in a mathematical form that a machine learning algorithm can understand. For example, two prompts with similar intent or tone will have embeddings that are close to each other in this high-dimensional space, even if they use different words.
Once every prompt was represented as a 384-dimensional vector, we used K-Means clustering to group similar prompts together. K-Means is an unsupervised algorithm that partitions the data into clusters by minimizing the distance between prompts in the same group.
We tested different numbers of clusters and finally chose six, as it provided a good balance between detail and interpretability. Each represents a distinct category of attack behavior:
| Cluster | Category | Number of Prompts | Explanation |
|---|---|---|---|
| Cluster 0 | Ambiguous Requests | 10,407 | Prompts that did not clearly fit into any other category. Their meaning is often vague, ambiguous, or contextually unclear. |
| Cluster 1 | Jailbreak & Roleplay Attacks | 8,824 | Prompts attempting to bypass safety filters using alter egos like DAN or simulated roleplay scenarios. |
| Cluster 2 | Financial Stuff & Fraud | 3,620 | Focused on investment scams, unethical financial planning, and manipulation of financial systems. |
| Cluster 3 | Toxicity, Hate Speech & Social Manipulation | 9,719 | Contains slurs, racism, sexism, and prompts encouraging danger and hate. |
| Cluster 4 | Violence & Illegal Activities | 11,422 | The most severe group, with prompts about physical violence, bomb-making, robbery, and other illegal activities. |
| Cluster 5 | Privacy Violations | 1,427 | Prompts focused on doxxing, harassment, and personal data extraction (e.g., asking for someone’s home address). |
The PCA (principal component analysis) plot below visualizes the distribution of clusters based on their embeddings. Here, we display only the two principal components to simplify and illustrate the underlying structure:
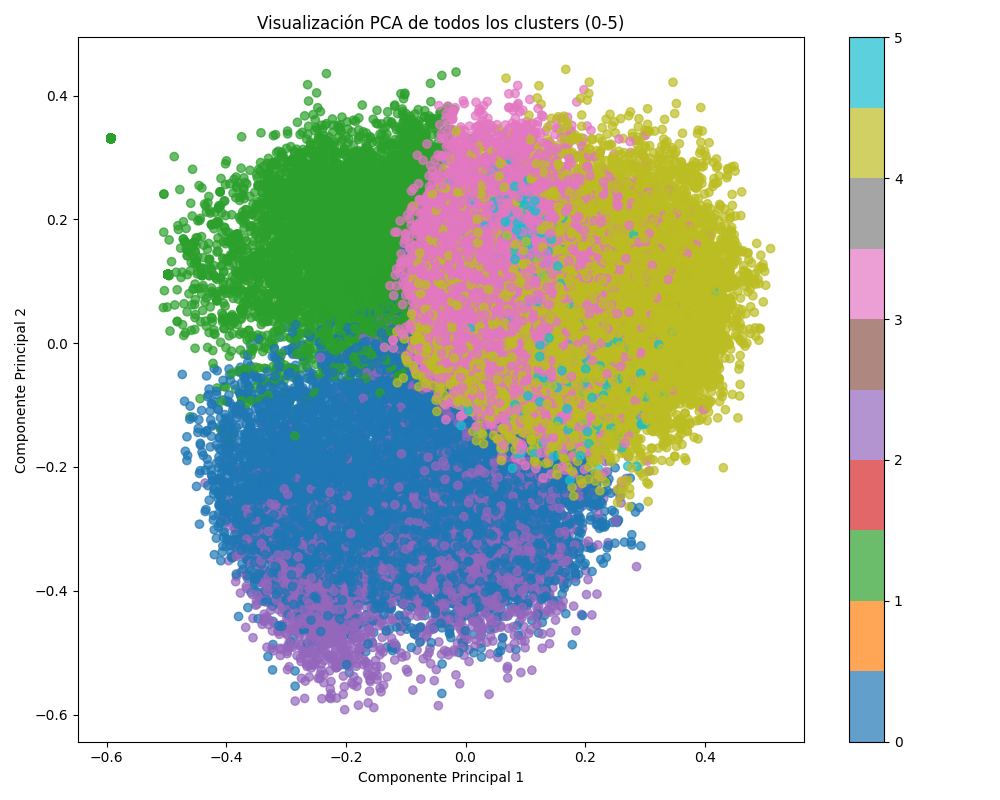
Cluster 0: Cleaning and Refinement
While analyzing the results, we noticed that Cluster 0 (Ambiguous Requests) initially contained a very wide variety of prompts that didn’t fit well into any specific attack category. Essentially, Cluster 0 acted as a “catch-all” group for diverse prompts, some of which were actually better suited for other clusters.
To fix this, we did a manual review and reorganization of Cluster 0. This means we looked closely at the prompts in this cluster and applied custom rules to decide where they really belonged.
We used things like text patterns (regex) to detect certain structures. Based on these patterns, we manually reviewed and reassigned some prompts to clusters where they semantically fit better. In certain cases, we needed to adjust the prompt slightly, for example, by simplifying or trimming it, before using its similarity to other prompts (measured by distance to cluster centers) to determine its best placement.
Not all prompts were moved. Some stayed in Cluster 0, but only after we were sure they didn’t strongly belong to another category. Finally, we even deleted from the dataset some prompts as they were considered to be neither helpful nor clear. In the end, this cleanup helped make Cluster 0 more consistent. Now it mostly contains genuinely ambiguous or subtly adversarial prompts, not just a random mix.
Cluster 1: Cleaning and Refinement
Cluster 1 was originally designed to group roleplay-based prompts, where users disguise harmful intent by asking the model to take on a character or scenario, like an uncensored AI, a secret agent, or a fictional setting.
However, upon review, we found that many prompts were not purely roleplay. A large portion were hybrids, where the roleplay acted as a wrapper for a specific attack (e.g., bomb-making, credit card fraud, money laundering).
To improve consistency, we applied a cleaning strategy to the majority of cases that followed a recognizable structure:
We also performed deduplication to remove near-identical templates.
As a result, Cluster 1 was significantly reduced in size, but is now more focused and contains mostly roleplay instructions only.
It is not 100% clean yet, as some edge cases remain, but we plan to address those in future iterations.
To support transparency and collaboration within the research community, we are publishing a curated subset of our red teaming dataset on Hugging Face: link here
This subset contains only prompts sourced from datasets with non-commercial licenses, carefully selected and cleaned by the Galtea team.
This release is intended to support reproducibility and accelerate research into adversarial prompt crafting and LLM safety testing.
To finish, this subset is our first try at organizing different types of harmful prompts using real examples. The categories we made come directly from the data we found, not from a fixed list or a formal threat model. This means our work shows only the kinds of attacks that appeared in the dataset, not all the possible ones. Our classification is similar but not equivalent to LlamaGuard categories or Ailuminate from MLCommons, which are relevant for more specific use cases. Our goal is to give a simple and useful starting point, based on real data, that others can build on. We hope this helps people test and improve red teaming methods, and maybe combine this with other safety tools and models in the future.
We’ll continue to share insights as we test and deploy new tools. If you’re building LLM products and want to harden them against real-world adversaries, we’re here to help.
Book a demo with us: Galtea Demo
Full list of datasets used
| DATASET | LICENSE |
|---|---|
| Deepset/prompt-injections | apache-2.0 |
| Verazuo/forbidden_question_set_with_prompts | MIT |
| Mpwolke/aart-ai-safety | CC BY-SA 4.0 |
| Reshabhs/SPML_Chatbot_Prompt_Injection | MIT |
| JailbreakBench/JBB-Behaviors | MIT |
| Walledai/AdvBench | MIT |
| GuardrailsAI/detect-jailbreak | MIT |
| Dynamoai/safe_eval | MIT |
| PKU-Alignment/PKU-SafeRLHF-30K | CC BY-NC 4.0 |
| PKU-Alignment/BeaverTails | CC BY-NC 4.0 |
| FreedomIntelligence/Ar-BeaverTails-Evaluation | apache-2.0 |
| Diaomuxi/SEAS | CC BY-NC 4.0 |